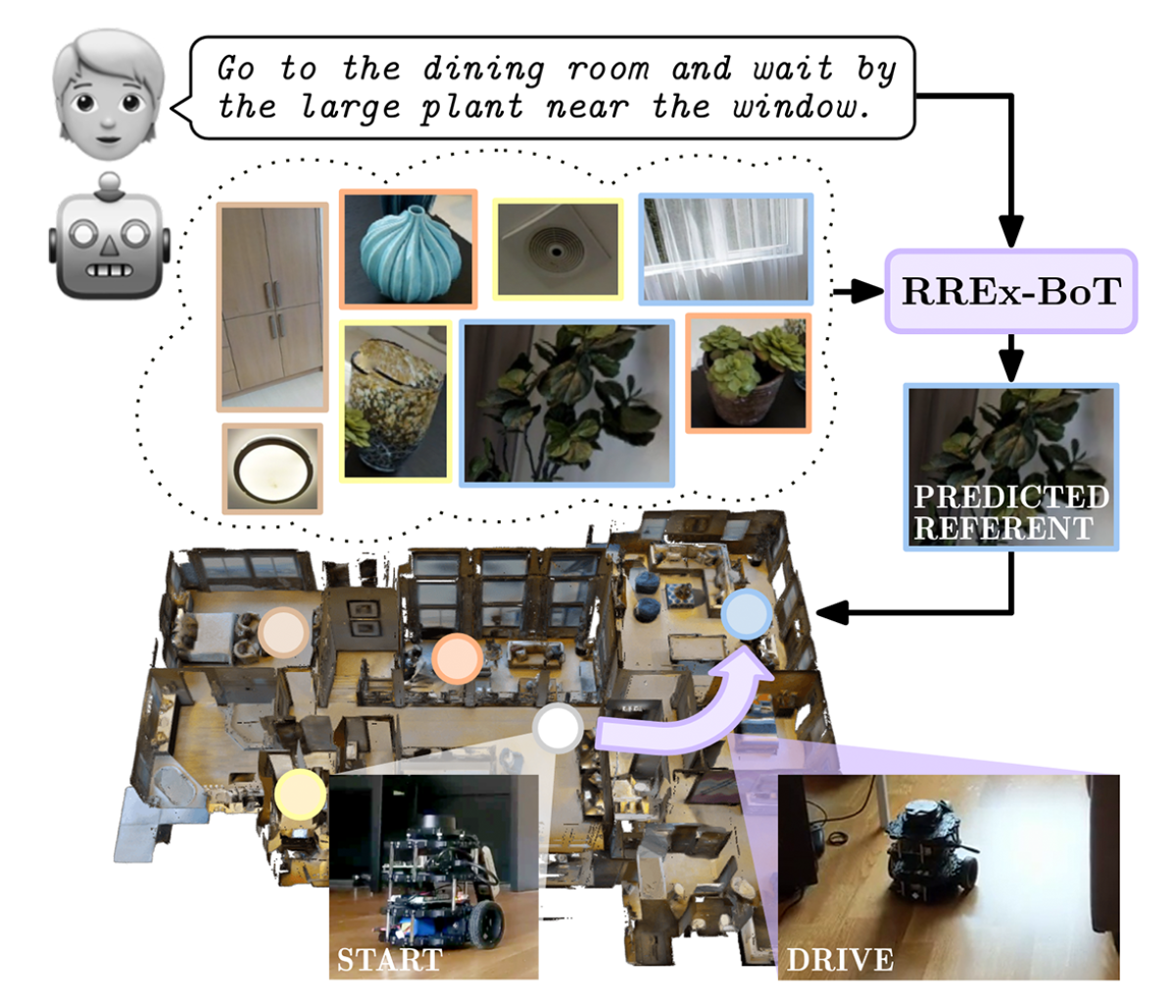
Remote-object grounding is the task of automatically determining where in the local environment to find an object specified in natural language. It is an essential capability for household robots, which need to be able to execute commands like “Bring me the pair of glasses on the counter in the kids’ bathroom.”
In a paper we are presenting at the International Conference on Intelligent Robots and Systems (IROS), my colleagues and I describe a new approach to remote-object grounding that leverages a foundation model — a large, self-supervised model that learns joint representations of language and images. By treating remote-object grounding as an information retrieval problem and using a “bag of tricks” to adapt the foundation model to this new application, we enable a 10% improvement over the state of the art on one benchmark dataset and a 5% improvement on another.
Language-and-vision models
In recent years, foundation models — such as large language models — have revolutionized several branches of AI. Foundation models are usually trained through masking: elements of the input data — whether text or images — are masked out, and the model must learn to fill in the gaps. Since masking requires no human annotation, it enables the models to be trained on huge corpora of publicly available data. Our approach to remote-object grounding is based on a vision-language (VL) model — a model that has learned to jointly represent textual descriptions and visual depictions of the same objects.

We consider the scenario in which a household robot has had adequate time to build up a 3-D map of its immediate environment, including visual representations of the objects in that environment. We treat remote-object grounding as an information retrieval problem, meaning that the model takes linguistic descriptions — e.g., “the glasses on the counter in the kids’ bathroom” — and retrieves the corresponding object in its representation of its visual environment.
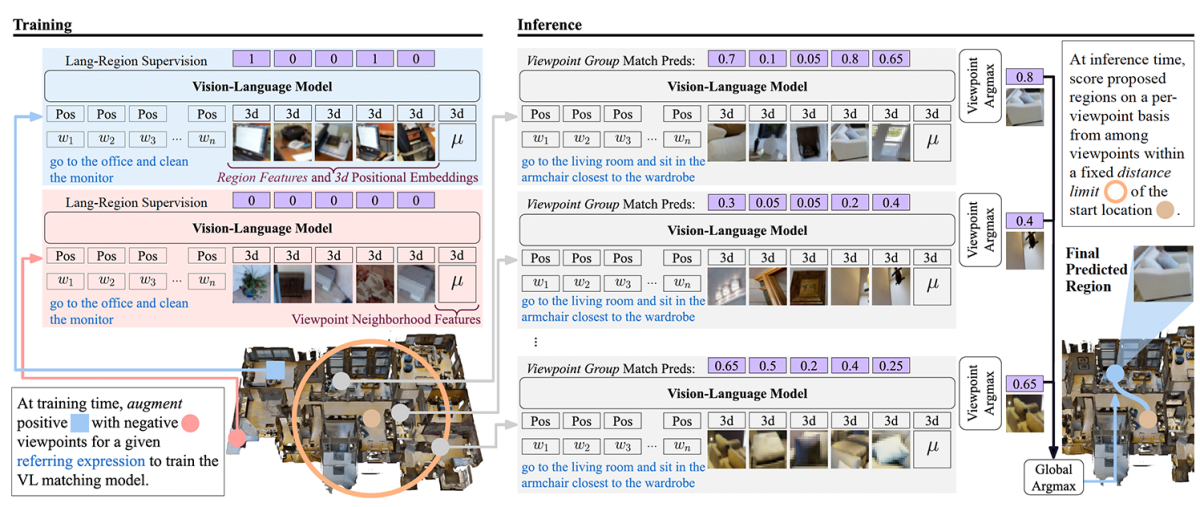
Adapting a VL model to this problem poses two major challenges. The first is the scale of the problem. A single household might contain 100,000 discrete objects; it would be prohibitively time consuming to use a large foundation model to query that many candidates at once. The other challenge is that VL models are typically trained on 2-D images, whereas a household robot builds up a 3-D map of its environment.
Bag of tricks
In our paper, we present a “bag of tricks” that help our model surmount these and other challenges.
1. Negative examples
The obvious way to accommodate the scale of the retrieval problem is to break it up, separately scoring the candidate objects in each room, say, and then selecting the most probable candidates from each list of objects.
The problem with this approach is that the scores of the objects in each list are relative to each other. A high-scoring object is one that is much more likely than the others to be the correct referent for a command; relative to candidates on a different list, however, its score might drop. To improve consistency across lists, we augment the model’s training data with negative examples — viewpoints from which the target objects are not visible. This prevents the model from getting overconfident in its scoring of candidate objects.
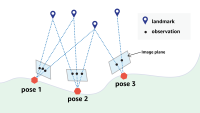
2. Distance-limited exploration
Our second trick for addressing the problem of scale is to limit the radius in which we search for candidate objects. During training, the model learns not only what objects best correspond to what requests but how far it usually has to go to find them. Limiting search radius makes the problem much more tractable with little loss of accuracy.
3. 3-D representations
To address the mismatch between the 2-D data used to train the VL model and the 3-D data that the robot uses to map its environment, we convert the 2-D coordinates of the “bounding box” surrounding an object — the rectangular demarcation of the object’s region of the image — to a set of 3-D coordinates: the three spatial dimensions of the center of the bounding box and a radius, defined as half the length of the bounding box’s diagonal.
4. Context vectors
Finally, we employ a trick to improve the model’s overall performance. For each viewpoint — that is, each location from which the robot captures multiple images of the immediate environment — our model produces a context vector, which is an average of the vectors corresponding to all of the objects visible from that viewpoint. Adding the context vector to the representations of particular candidate objects enables the robot to, say, distinguish the mirror above the sink in one bathroom from the mirror above the sink in another.
We tested our approach on two benchmark datasets, each of which contains tens of thousands of commands and the corresponding sets of sensor readings, and found that it significantly outperformed the previous state-of-the-art model. To test our algorithm’s practicality, we also deployed it on a real-world robot and found that it was able to execute commands in real time with high accuracy.