
Virtually all the images flying over the Internet are compressed to save bandwidth, and usually, the codecs — short for coder-decoder — that do the compression, such as JPG, are hand crafted.
In theory, machine-learning-based codecs could provide better compression and higher image quality than hand-crafted codecs. But machine learning models are trained to minimize some loss metric, and existing loss metrics, such as PSNR and MS-SSIM, do not align well with human perception of similarity.
In January, at the IEEE Winter Conference on Applications of Computer Vision (WACV), we presented a perceptual loss function for learned image compression that addresses this issue.

We also describe how to incorporate saliency into a learned codec. Current image codecs, whether classical or learned, tend to compress all regions of an image equally. But most images have salient regions — say, faces and texts — where faithful reconstruction matters more than in other regions — say, sky and background.
Compression codecs that assign more bits to salient regions than to low-importance regions tend to yield images that human viewers find more satisfying. Our model automatically learns from training data how to trade off the assignment of bits to salient and non-salient regions of an image.
In our paper, we also report the results of two evaluation studies. One is a human-perception study in which subjects were asked to compare decompressed images from our codec to those of other codecs. The other study used compressed images in downstream tasks such as object detection and image segmentation.
In the first study, our method was the clear winner at bit rates below one bit per image pixel. In the second study, our method was the top performer across the board.
Model-derived losses
Several studies have shown that the loss functions used to train neural networks as compression codecs are inconsistent with human judgments of quality. For instance, of the four post-compression reconstructions in the image below, humans consistently pick the second from the right as the most faithful, even though it ranks only third according to the MS-SSIM loss metric.

It’s also been shown, however, that intermediate values computed by neural networks trained on arbitrary computer vision tasks — such as object recognition — accord better with human similarity judgments than conventional loss metrics.
That is, a neural network trained on a computer vision task will generally produce a fixed-length vector representation of each input image, which is the basis for further processing. The distance between the values of that vector for two different images is a good predictor of human similarity judgments.
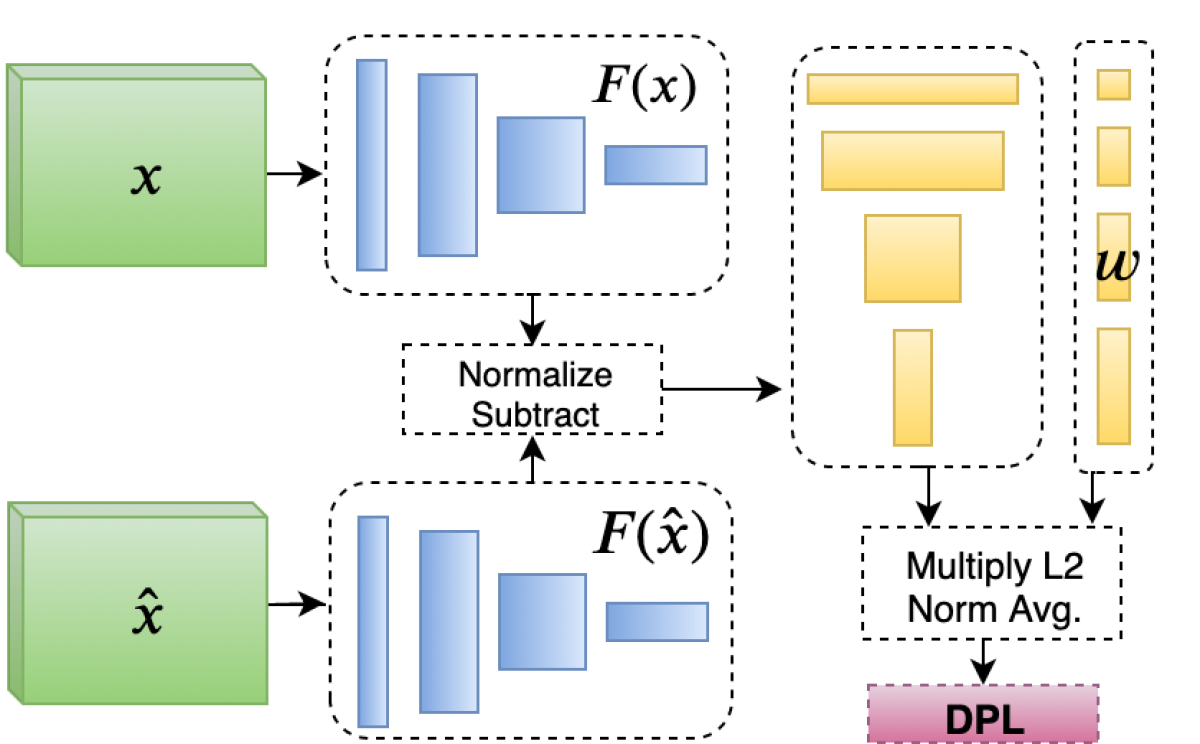
We drew on this observation to create a loss function suitable for training image compression models. In other words, to train our image compression model, we used a loss function computed by another neural network. We call this deep perceptual loss.
First, we created a compression training set using the two-alternative forced-choice (2AFC) methodology. Annotators are presented with two versions of the same image reconstructed from different compression methods (both classical and learned codecs), with the original image between them. They are asked to pick the image that is closer to the original. On average, the annotators spent 56 seconds on each sample.
We split this data into training and test sets and trained a network to predict which of each pair of reconstructed images human annotators preferred. Then we extracted the encoder that produces the vector representation of the input images and used it as the basis for a system that computes a similarity score (above).

In the table at right, we can see that, compared to other metrics, our approach (LPIPS-Comp VGG PSNR) provides the closest approximation (81.9) of human judgment (82.06). (The human-judgment score is less than 100 because human annotators sometimes disagree about the relative quality of images.) Also note that MS-SSIM and PSNR loss are the lowest-scoring metrics.
The compression model
Armed with a good perceptual-loss metric, we can train our neural codec. So that it can learn to exploit saliency judgments, our codec includes an off-the-shelf saliency model, trained on a 10,000-image data set in which salient regions have been annotated. The codec learns how to employ the outputs of the saliency model independently, based on the training data.
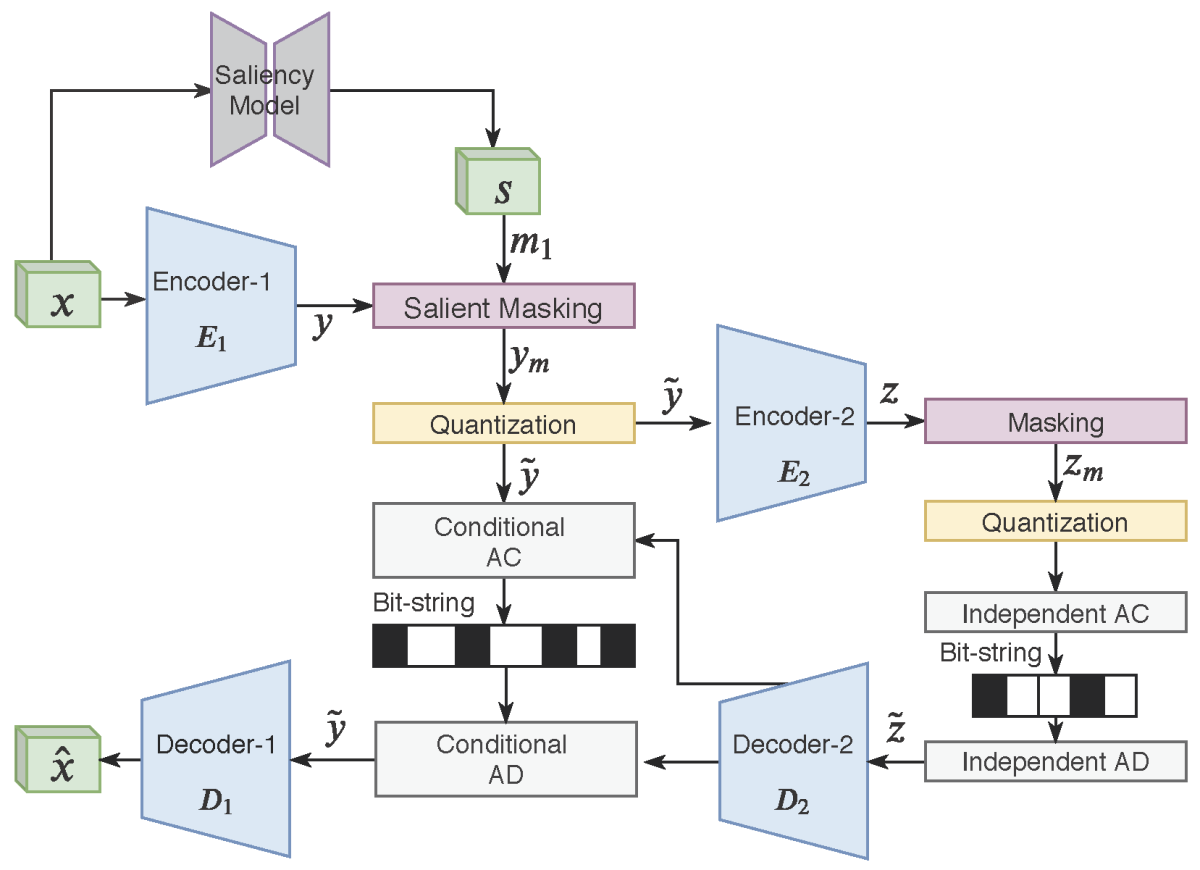
In our paper, we report an extensive human-evaluation study that compared our approach to five other compression approaches across four different bits-per-pixel values (0.23, 0.37, 0.67, 1.0). Subjects judged reconstructed images from our model as closest to the original across the three lowest bit-rates. At a bit rate of 1.0 bits per pixel, the BPG method is the top performer.
We did another experiment where we compressed images from the benchmark COCO dataset using traditional and learned image compression approaches. We then used these compressed images for other tasks, such as instance segmentation (finding the boundaries of objects) and object recognition. The reconstructed images from our approach delivered superior performance across the board, since our approach better preserves salient aspects in an image.
A compression algorithm that preserves important aspects of an image at various compression rates benefits Amazon customers in several ways, such as reducing the cost of cloud storage and speeding the download of images stored with Amazon Photos. Delivering those types of concrete results to our customers was the motivation for this work.



