
In recent years, automatic speech recognition (ASR) has moved to all-neural models. Connectionist-temporal-classification loss functions are an attractive option for ASR (and specifically end-to-end ASR) because they make predictions without conditioning on previous context, thereby yielding simple models with low inference latency.
Unlike earlier, hybrid ASR models, which used lexicons to match phonemes to word candidates, all-neural models are hard to adapt to rare or unfamiliar words. Biasing connectionist-temporal-classification (CTC) models to new words is particularly difficult because of the lack of context: i.e., the model’s prediction at any given time step is independent of the outputs at the previous time steps, the same prediction scheme that enables decoding with low inference latency.

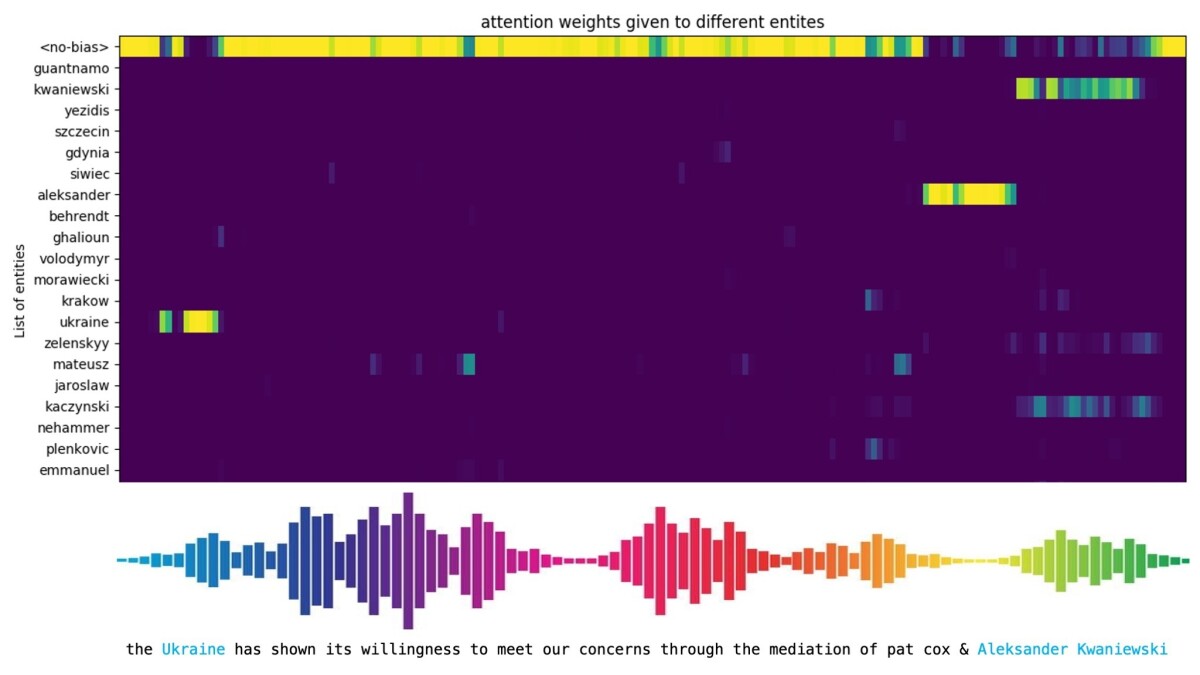
This is a problem for ASR applications in which the operational vocabulary is constantly changing, as when new names — say, “Zelenskyy” — enter the conversation, or when users add new names to their address books. Retraining the ASR model on new datasets featuring new words is a prohibitively time-consuming and computationally intensive way to update large models.
In a paper we presented at this year’s Spoken Language Technologies (SLT) Workshop, we describe a method for enabling a CTC model to correctly transcribe new entity names without the need for retraining. The method includes a variety of techniques for biasing the model toward names on a list. These techniques apply to both the model’s encoder, which converts inputs into vector representations, and its beam search decoder, which evaluates candidate output sequences. The techniques can be applied in combination to maximize the likelihood of accurate transcription.
On a dataset with difficult medical terminology like names of diseases and medicines, our method improves the ASR model’s F1 score (which factors in both false negatives and false positives) on these entities from 39% in a model without biasing to 62%. Similarly, on a publicly available Vox Populi benchmark that contains recordings of the European Parliament, our method improves the F1 recognition scores of rare entities (names of cities, people, etc.) from 49% to 80% without any retraining of the base ASR model.
Biasing
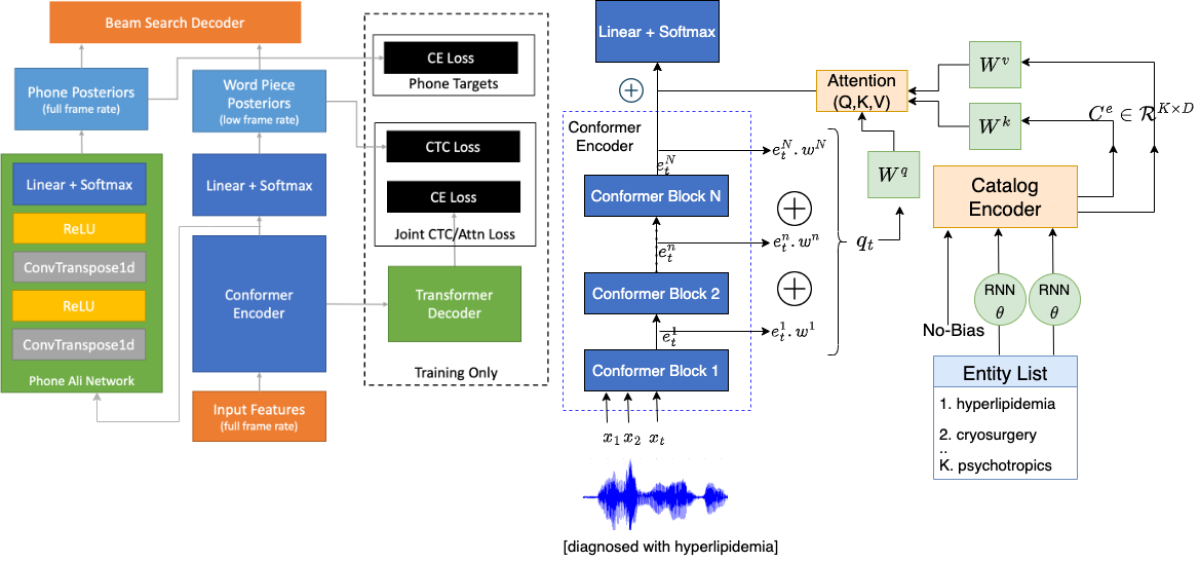
Our baseline CTC model is an all-neural network that takes frames of audio (snapshots of the signal spectrum across small durations) as input and converts them into a sequence of probability distributions over subword units — word fragments that can be composed into full words. These probability distributions are represented by a weighted graph of possible subword sequences. To rank candidate word sequences, the model decoder uses beam search combined with an external language model (LM), which encodes the probabilities of sequences of words.

Encoder biasing
To bias the CTC model’s encoder, we use a contextual adapter, a separate module that is trained after we have frozen the weights of the base CTC model. The adapter takes the set of rare words in training examples as inputs and learns a mapping between the words’ subword-unit sequences and their audio representations.
In our base network, we use additional CTC losses to train representations from intermediate layers of the encoder (the 6thand the 12th) to produce subword sequences. This enables the model to use approximations of the outputs in previous time steps to influence prediction of the current frame. Our adapter uses a weighted sum of representations from these intermediate layers as audio representations, thereby countering the conditional-independence assumption of CTC models.
At inference time, we use the contextual adapter to embed a list of rare or out-of-vocabulary (OOV) entity names, and at every time frame of the audio, an attention module tries to match the name embeddings with the audio representation. The attention module can also choose to ignore all of the names by attending to a special <no-bias> token. If the audio does contain some entity from the provided list, the probability of the corresponding sequence of subword units is increased.
Decoder biasing
We obtained positive results with the following techniques for decoder biasing. All of these techniques are applied directly at inference time:

- Adaptive subword boosting in beam search decoding: We dynamically boost the probability of a top-k subword sequence if it begins with a subword that appears on the custom entity list. For example, if “Fremont” is one of the custom words, then if the subword “fre” appears, we boost the probabilities of the subsequent subwords “mo” and “nt”. The boosting score for each subword candidate at time step t is determined dynamically by the difference between its log probability and that of the top-1 hypothesis.
- Unigram boosting: We boost the probabilities of words on the list of entity names by adding them to the external LM through an OOV/BOOST class, to keep the LM unmodified during inference.
- Phonetic-distance-based rescoring: We take the outputs of the intermediate-layer network — which are phones, or phonetic representations of short speech sounds — and perform forced alignment between them and the output of the CTC model. We compute the cost of this alignment and use it to rescore the n-best lists.
- Pronunciation-based lexicon lookup: For rare and OOV words, our phone prediction hypotheses are more accurate than our subword predictions. Therefore, we used forced alignment with the phone predictions of the intermediate-layer network to identify the boundaries between words in the phone sequence. If the sequence of phones corresponding to a word is an exact match for the pronunciation of a word in the lexicon, we replace the word with the lexicon entity.
- Grapheme-to-grapheme (G2G) techniques: A grapheme is the smallest meaningful unit of written text. We use a table that maps individual graphemes to their multiple possible pronunciations (i.e., phones) to resolve alternative pronunciations of the words on our list of entity names. The probability of predicting the actual word improves with an increase in the number of these G2G variants.
Joint model
Finally, we present a joint model that combines the encoder- and decoder-biasing techniques described above, and as expected, the techniques are complementary to each other and result in additive gains. Conceptually, the encoder-biasing method aids in generating higher-probability scores for the rare subwords it copies, which helps prevent rare subwords from getting pruned during the beam-search decoding of the subword graph. The rare and OOV words get a further boost from the decoder-biasing techniques, which promote the rare-word candidate paths through the graph to top ranking.
We hope our methodology advances the speech community in the direction of zero-shot personalized ASR for CTC models, which are becoming an increasingly prevalent choice for ASR systems.



