
Embodied artificial intelligence (EAI) aims to train embodied agents to solve challenging multimodal tasks involving navigation and object manipulation within an interactive simulation environment. Developing such embodied agents requires long-horizon planning, vision-and-language grounding, and developing highly sample-efficient algorithms.
At last year’s International Conference on Intelligent Robots and Systems (IROS), we presented two papers that advance EAI. In the first, “DialFRED: Dialogue-enabled agents for embodied instruction following”, we present DialFRED, an embodied-instruction-following benchmark containing 53,000 human-annotated dialogues that enables an agent to (1) to engage in an active dialogue with the user and (2) use the resulting information to better complete tasks. The DialFRED source code and datasets are publicly available, to encourage researchers to propose and evaluate dialogue-enabled embodied agents.

In the second, “Learning to act with affordance-aware multimodal neural slam”, we first identify that the essential bottleneck in embodied tasks is the ability of the agent to perform planning and navigation. To tackle this challenge, we adopt a neural approach to perform simultaneous localization and mapping (SLAM) that is affordance aware, meaning that it models how objects in the environment can be used. This is the first affordance-aware neural SLAM model that uses both vision and language for exploration.
DialFRED
In current benchmarks, such as ALFRED, the embodied agent is given a language instruction and is expected to execute the sequence of actions (action trajectory) required to complete the associated task in a simulated environment, such as AI2Thor.
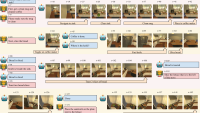
Agents often find such tasks overwhelming because of two difficulties: (1) resolving ambiguities in natural language and mapping instructions to actions in a complex environment and (2) planning for long-horizon trajectories and recovering from possible failures. Conversational interactions with human operators can help with both.
Data collection
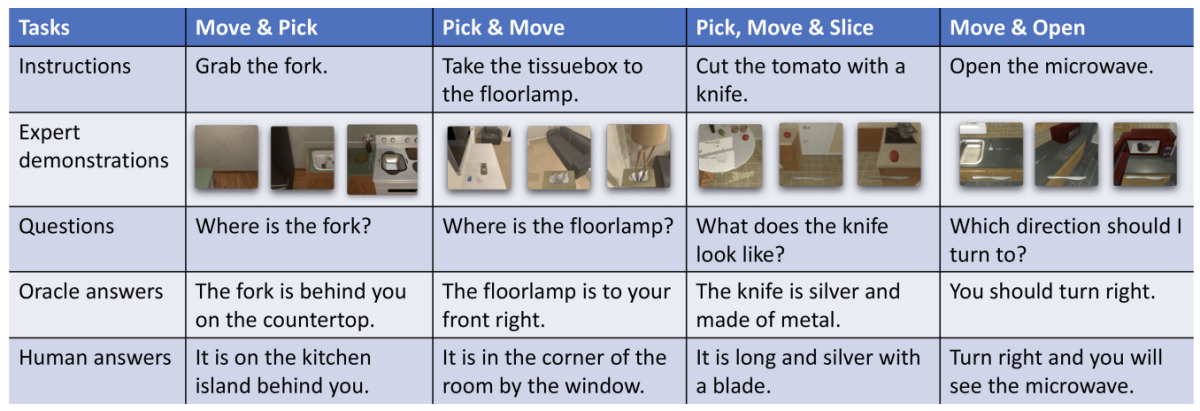
We devised a novel, low-cost, and scalable methodology for data collection using Amazon Mechanical Turk. Unlike prior methods, it didn’t require complex services for the pairing of two humans for data collection.
With our method, a video demonstration of a task is shown to an annotator. The video pauses at the beginning of every sub-task, and the annotator receives an instruction corresponding to the sub-task and a request to generate a question or questions that help to clarify or complete the sub-task. The annotator then watches the next segment of video and proposes answers to the questions. This methodology produces training examples consisting of language instructions and images of the environment from the robot’s point of view.
Dialogue generation using reinforcement learning
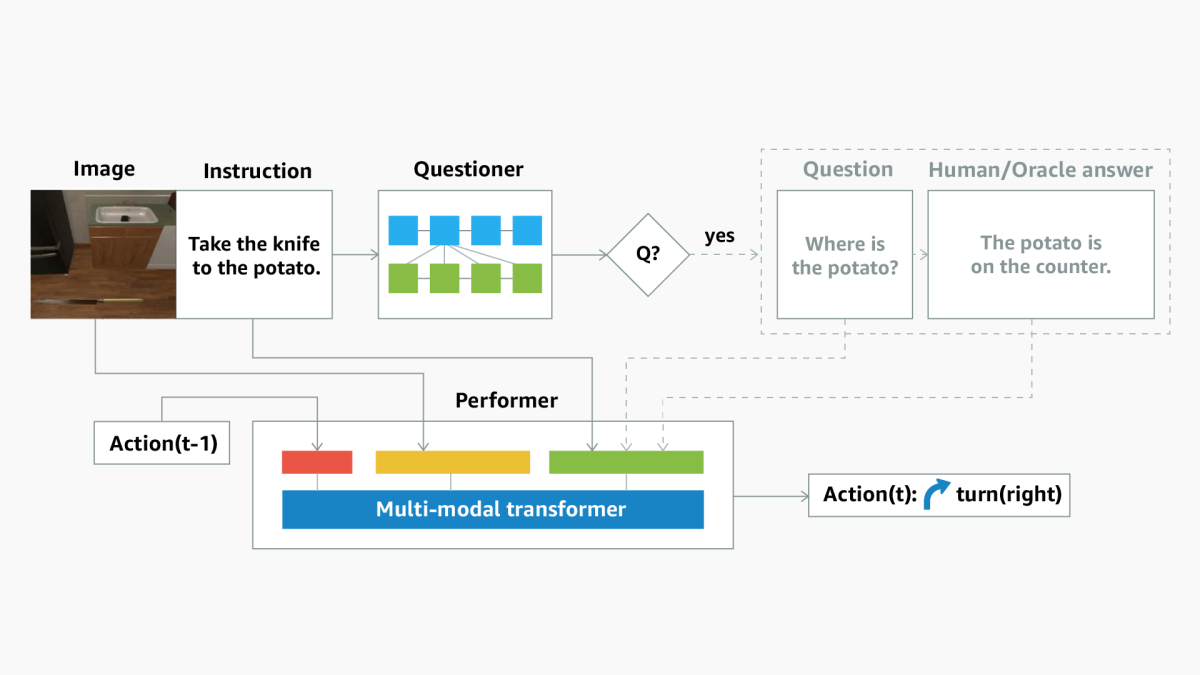
DialFRED incorporates a new questioner-performer framework for building embodied dialogue agents. The questioner model is pretrained with the human-annotated dialogue sessions and predicts when to ask clarification questions. It also generates the questions pertinent to a given situation.

Through reinforcement learning, the questioner model is fine-tuned to ask the right types of questions at the right time to benefit task completion. The DialFRED framework also includes an oracle that automatically generates answers to the generated questions, using ground-truth metadata from the simulation environment. DialFRED thus provides an interactive Q&A framework for training embodied dialogue agents.
The performer then uses the information from the questions and answers (in addition to the original task instructions) to generate the action sequences — or trajectories — for completing the task.
This questioner-performer model achieves a 33.6% success rate on an unseen validation set, compared to 18.3% for a model that passively follows instructions.
DialFRED Leaderboard
To advance the research and development of embodied dialogue agents, we also created a DialFRED leaderboard on EvalAI, where participating researchers can directly submit their action trajectories to benchmark their embodied agents on a new unseen test set.
Affordance-aware SLAM
Our neural SLAM approach involves building an affordance-aware semantic map and planning over this map at the same time. This significantly reduces the sample complexity, leads to efficient long-horizon planning, and enables vision-and-language grounding. Our approach enables a more than 20% absolute improvement over prior work on the ALFRED benchmark and achieves a new state-of-the-art generalization performance at 19.95%.
Modeling approach
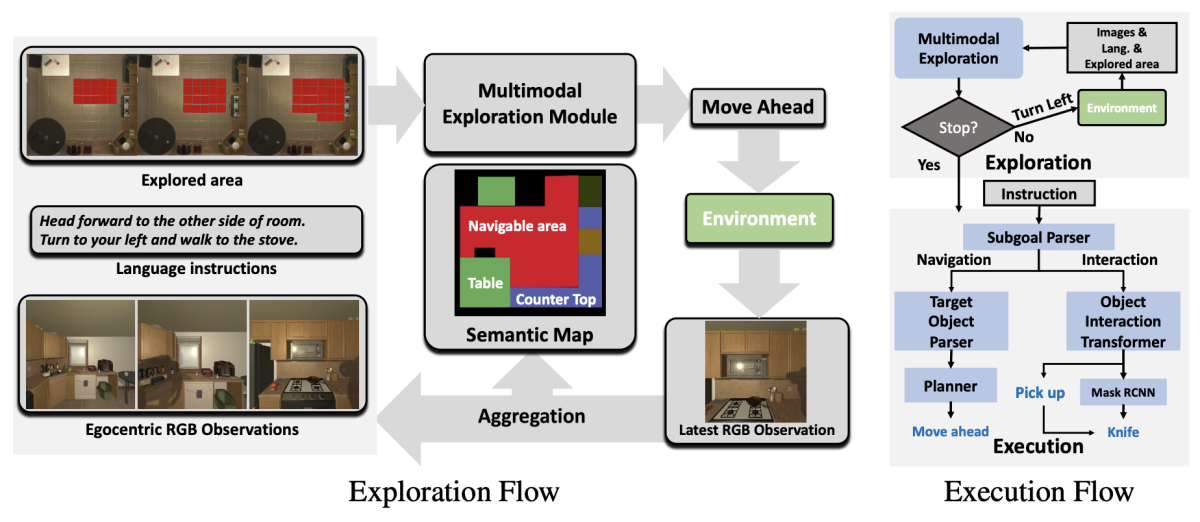
For a given task, T, specified by a high-level goal description (such as “Heat some water in a pan”) and low-level human instructions (such as “Head forward to the other side of the room. Turn to your left and walk to the stove”), our method proceeds in two phases:
- Exploration: The agent aims to explore the environment, given the low-level language instructions, the previous exploration actions, and area that the agent has already visited and observed.
- Execution: Given the language instructions and the affordance-aware semantic representation (i.e., the semantic map) acquired during exploration, the agent executes the subgoals sequentially. It uses a planning module (which consumes the semantic map) for navigation subgoals and an object interaction transformer for other subgoals.
To improve exploration performance, we propose a multimodal module that, at each step, selects one of three actions — MoveAhead, RotateLeft, or RotateRight — by making visual observations and factoring in past actions, the step-by-step language instructions, and the map of previously explored areas. Our model is the first multimodal neural SLAM module to successfully handle ALFRED’s long-horizon-planning and affordance-aware-navigation challenges.
Acknowledgements: Govind Thattai, Xiaofeng Gao



