
In 2018, Amazon launched a feature in the U.S. that enables Alexa to whisper back when whispered to, a feature that was expanded to all Alexa locales in November 2019. In a paper appearing in the January 2020 issue of the journal IEEE Signal Processing Letters, we describe the research that enabled that expansion.
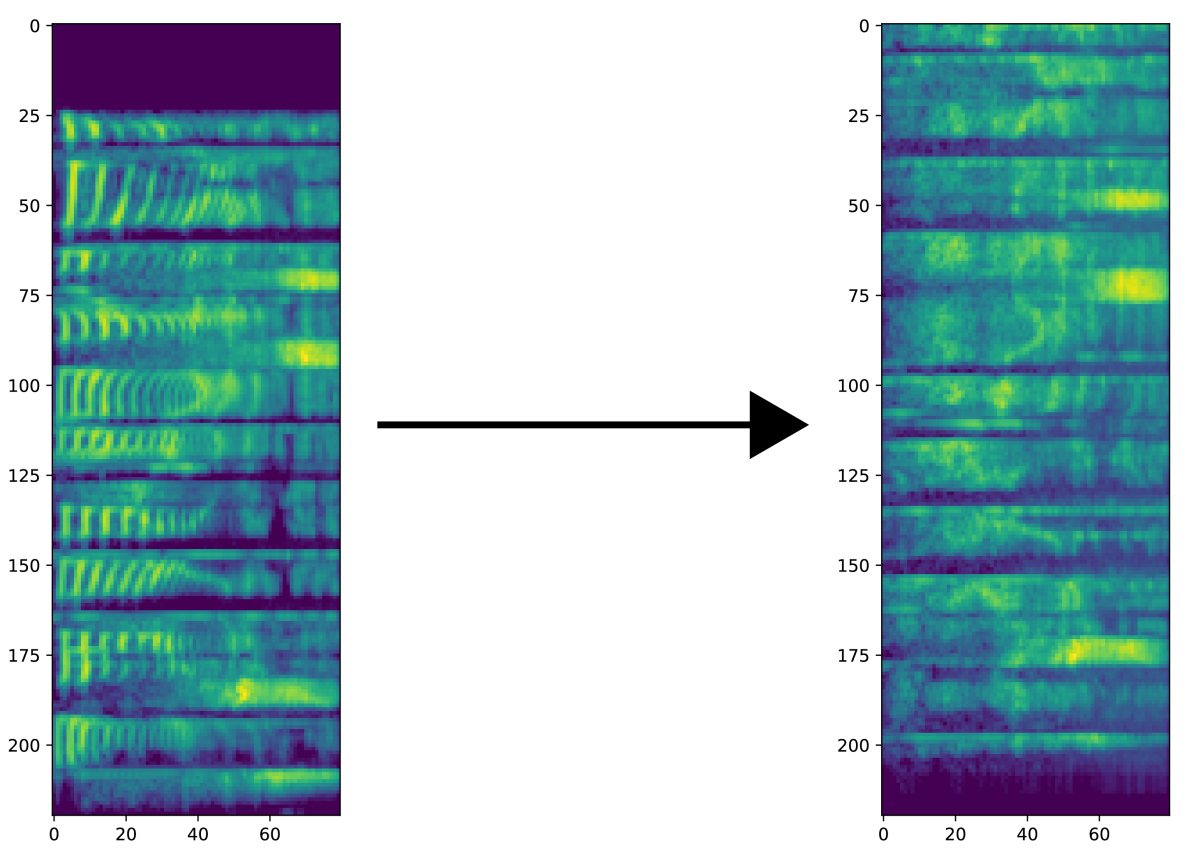
Our goal: convert normal speech into whispered speech while maintaining high naturalness and speaker identity. In the paper, we examined three different techniques for performing this conversion: a handcrafted digital-signal-processing (DSP) technique based on acoustic analysis of whispered speech and two different machine learning techniques, one that uses Gaussian mixture models (GMMs) and another that uses deep neural networks (DNNs). We evaluated all three methods through listener studies using the MUSHRA (multiple stimuli with hidden reference and anchor) methodology.
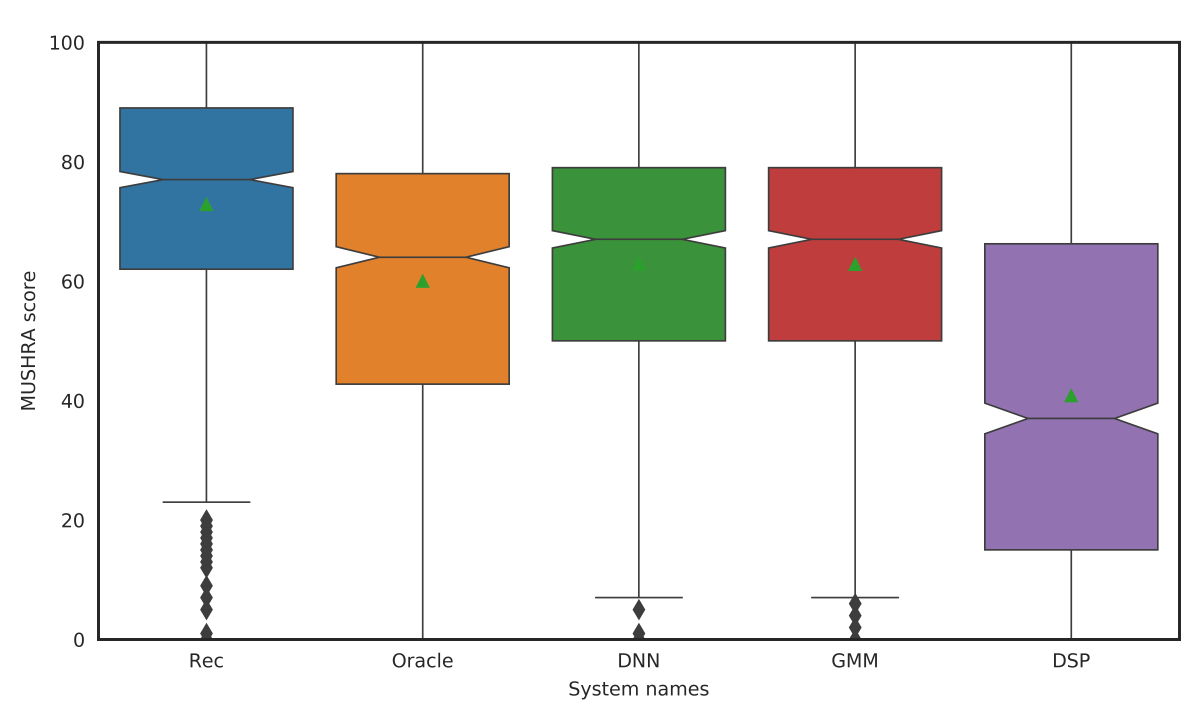
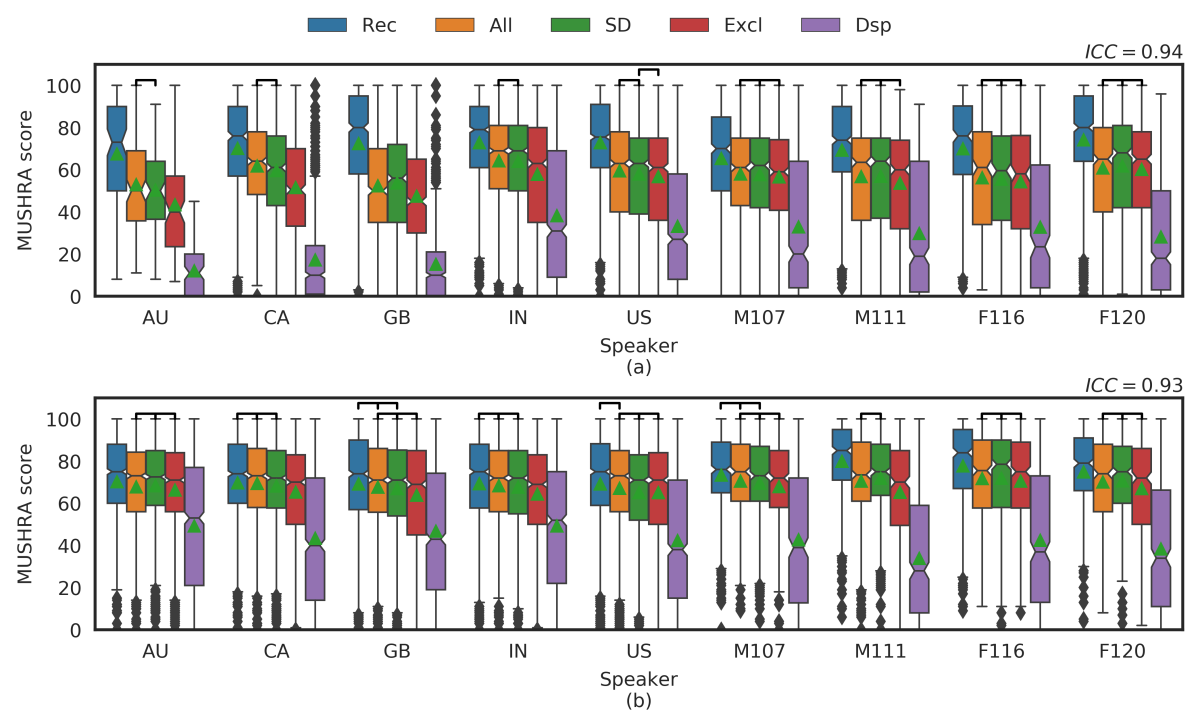
We found that, when the machine learning models were applied to the same speaker they had been trained on, their performance was roughly equivalent, and both outperformed the handcrafted signal processor. But the DNN model generalized much more readily to multiple and unfamiliar speakers.
U.S. English
Indian English
Mexican Spanish
Japanese
In 2017, we used the DSP technique to add whisper to all the voices available through Amazon Polly, the text-to-speech service provided to Amazon Web Services customers. It was based on a large body of scientific literature analyzing the acoustic differences between whispered and fully voiced speech.
The two machine learning techniques (GMMs and DNNs) are instances of an approach called voice conversion. Voice conversion represents the speech signal using a set of acoustic features and learns to map the features of normally voiced speech onto those of whispered speech.
GMMs attempt to identify a range of values for each output feature — a Gaussian distribution over outputs — that correspond to a related distribution of input values. The combination of multiple distributions is what makes it a “mixture”. DNNs are dense networks of simple processing nodes whose internal settings are adjusted through a training process in which the network attempts to predict the outputs associated with particular sample inputs.
Voice conversion techniques have been used for a long time to make recordings of a source speaker sound more like those of a target speaker. They've also been used to try to reconstruct normal speech from whispered speech — in the case of laryngectomy patients, for instance. But this is the first time that they have been applied to the reverse problem.
We used two different data sets to train our voice conversion systems, one that we produced ourselves using professional voice talent and one that is a standard benchmark in the field. Both data sets include pairs of utterances — one in full voice, one whispered — from many speakers.
Like most neural text-to-speech systems, ours passes the acoustic-feature representation to a vocoder, which converts it into a continuous signal. To evaluate our voice conversion systems, we compared their outputs to both recordings of natural speech and recordings of natural speech fed through a vocoder (our “oracle”). This allowed us to gauge how well the voice conversion system itself was performing, independent of any limitations imposed by the need for vocoding.
In our first set of experiments, we trained the voice conversion systems on data from individual speakers and then tested them on data from the same speakers. We found that, while the raw recordings sounded most natural, whispers synthesized by our voice conversion models sounded more natural than vocoded human speech.
We then explored the ability of the conversion models to generalize to unseen speakers. First, we trained models on the full set of speakers from each data set and applied them to the same speakers. Then we trained the models on all but one speaker from each data set and applied it only to the held-out speaker.
In our experiments, we used only the open-source WORLD vocoder. However, in the version of our system that we have deployed to customers in all Alexa locales, we use a state-of-the-art neural vocoder that enhances the quality of the whispered speech even further. That’s the version that we used to generate the samples above.



