For years, Amazon researchers have been exploring the topic of extreme multilabel classification (XMC), or classifying inputs when the space of possible classification categories is large — say, millions of labels. Along the way, we’ve advanced the state of the art several times.
But that prior work was in the setting of a classic classification problem, where the model computes a probability for each label in the space. In a new paper that my colleagues and I presented at the biennial meeting of the European chapter of the Association for Computational Linguistics (EACL), we instead approach XMC as a generative problem, where for each input sequence of words, the model generates an output sequence of labels. This allows us to harness the power of large language models for the XMC task.
In this setting, however, as in the classic setting, the difficulty is that most of the labels in the XMC label space belong to a long tail with few representative examples in the training data. Past work addressed this problem by organizing the label space in a hierarchy: the input is first classified coarsely, and successive refinements of the classification traverse the hierarchical tree, arriving at a cluster of semantically related concepts. This helps the model learn general classification principles from examples that are related but have different labels, and it also reduces the likelihood that the model will get a label completely wrong.

In our paper, we do something similar, using an ancillary network to group labels into clusters and using cluster information to guide the generative model’s output. We experiment with two different ways of providing this guidance during training. In one, we feed a bit vector indicating which clusters are applicable to a text input directly into the generative model. In the other, we fine-tune the model on a multitask objective: the model learns to predict both labels from cluster names and cluster names from texts.
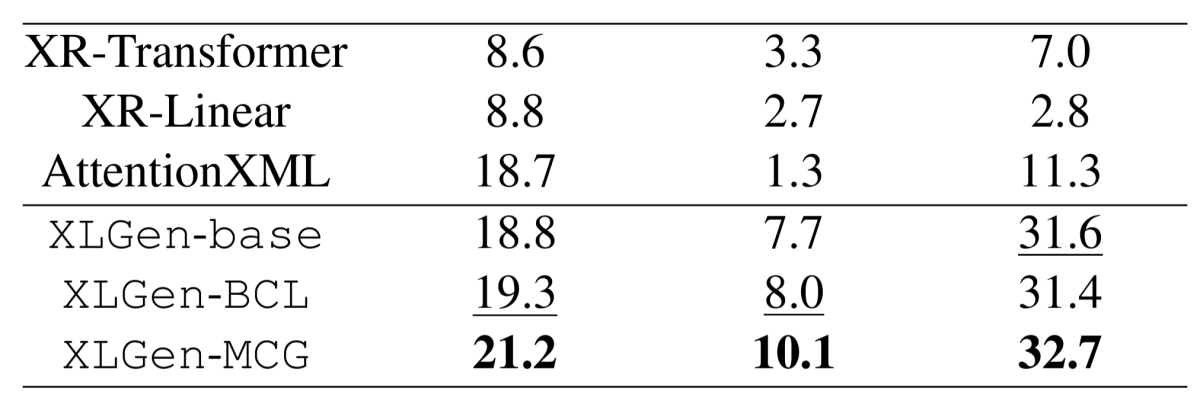
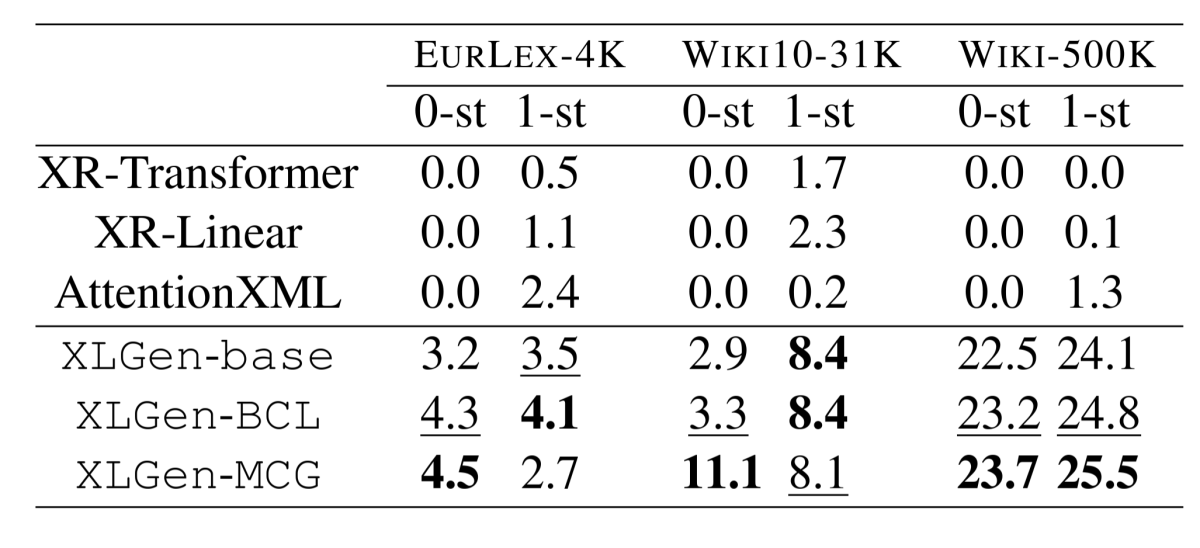
In tests, we compared both of these approaches to state-of-the-art XMC classifiers and a generative model fine-tuned on the classification task without the benefit of label clusters. Across the board, the generative models with clustering outperformed the traditional classifiers. In six out of eight experiments, at least one type of cluster-guided model matched or improved on the baseline generative model’s performance across the entire dataset. And in six experiments on long-tail (rare) labels, at least one cluster-guided model outperformed the generative baseline.
Architectures
We consider the task in which a model receives a document — such as a Wikipedia entry — as input and outputs a set of labels that characterize its content. To fine-tune the generative model, we use datasets containing sample texts and labels applied to them by human annotators.
As a baseline generative model, we use the T5 language model. Where BERT is an encoder-only language model, and GPT-3 is a decoder-only language model, T5 is an encoder-decoder model, meaning that it uses bidirectional rather than unidirectional encoding: when it predicts labels, it has access to the input sequence as a whole. This suits it well for our setting, where the order of the labels is less important than their accuracy, and we want the labels that best characterize the entire document, not just subsections of it.
To create our label clusters, we use a pretrained model to generate embeddings for the words of each document in the training set — that is, to map them to a representational space in which proximity indicates semantic similarity. The embedding of a given label is then the average embedding of all the documents that contain it. Once the labels are embedded, we use k-means clustering to organize them into clusters.
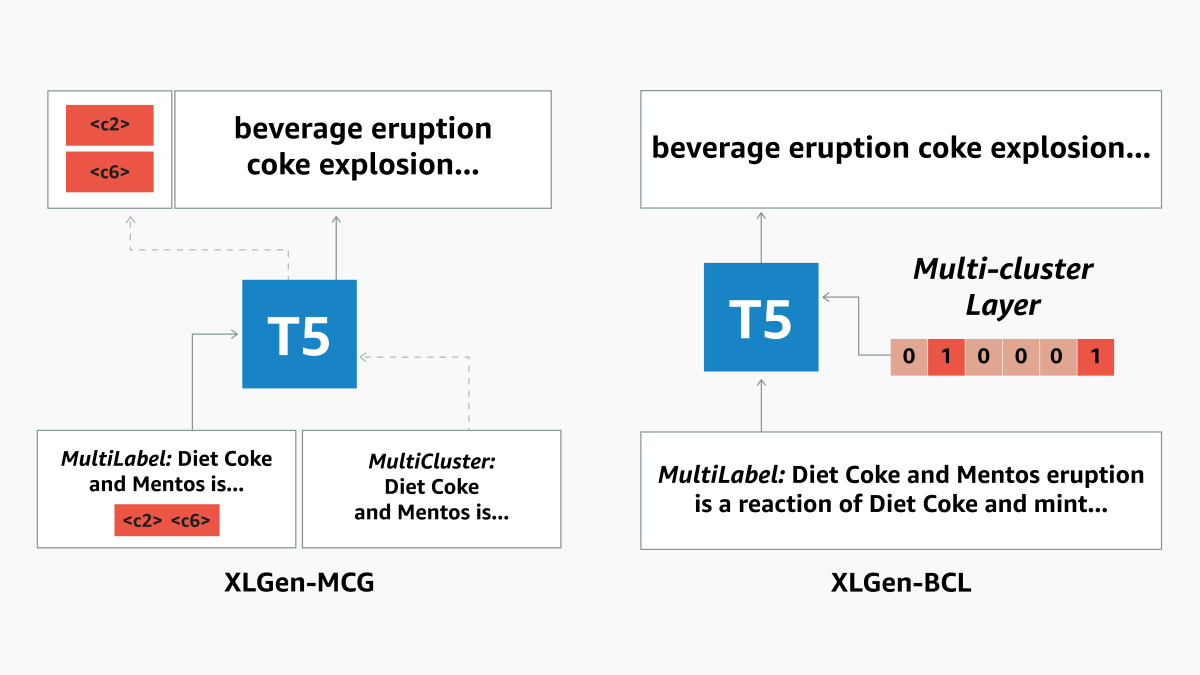
In the first architecture we consider, which we call XLGen-BCL, the ground-truth label clusters for a given document are represented as ones in a bit array; all other clusters are represented as zeroes. During training, the array passes to the model as an additional input, but at inference the time, the model receives text only.

In the other architecture, XLGen-MCG, the clusters are assigned numbers. The model is trained on a multitask objective, simultaneously learning to map cluster numbers to labels and texts to cluster numbers. At inference time, the model receives text only. First, it assigns the text a set of cluster numbers, and then it maps the cluster numbers to labels.
Experiments
We evaluated our two cluster-guided generative models and four baselines using four datasets, and on each dataset, we evaluated both overall performance and performance on rare (long-tail) labels. In assessing overall performance, we used F1 score, which factors in both false positives and false negatives, and we used two different methods to average per-label F1 scores. Macro averaging simply averages the F1 scores for all labels. Micro averaging sums all true and false positives and false negatives across all labels and computes a global F1 score.
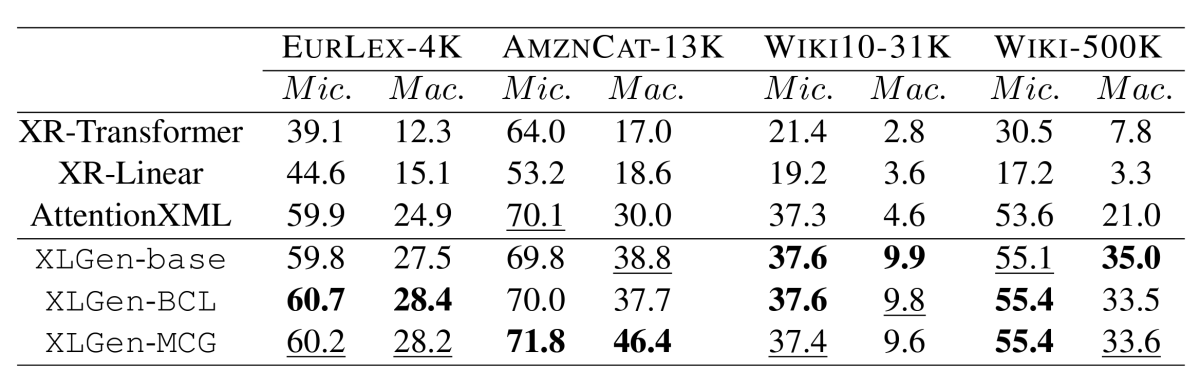
In assessing performance on long-tail labels, we considered labels that occurred only once or not at all in the training data.
We also conducted a set of experiments using positive and unlabeled (PU) data. That is, for each training example, we removed half of the ground truth labels. Since a label removed from one example might still feature in a different example, it could still feature as an output label. The experiment thus evaluated how well the models generalized across labels.
On the PU data, the generative models dramatically outperformed the traditional classifiers, and the XLGen-MCG model significantly outperformed the generative baseline.