
Virtual adversarial training (VAT) is a way to improve machine learning systems by creating difficult-to-classify training examples through the addition of noise to unlabeled data. It has had great success on both image classification tasks and text classification tasks, such as determining the sentiment of a review or the topic of an article.
It’s not as well adapted, however, to sequence-labeling tasks, in which each word of an input phrase gets its own label. Largely, that’s because VAT is difficult to integrate with conditional random fields, a statistical-modeling method that has proven vital to state-of-the-art performance in sequence labeling.
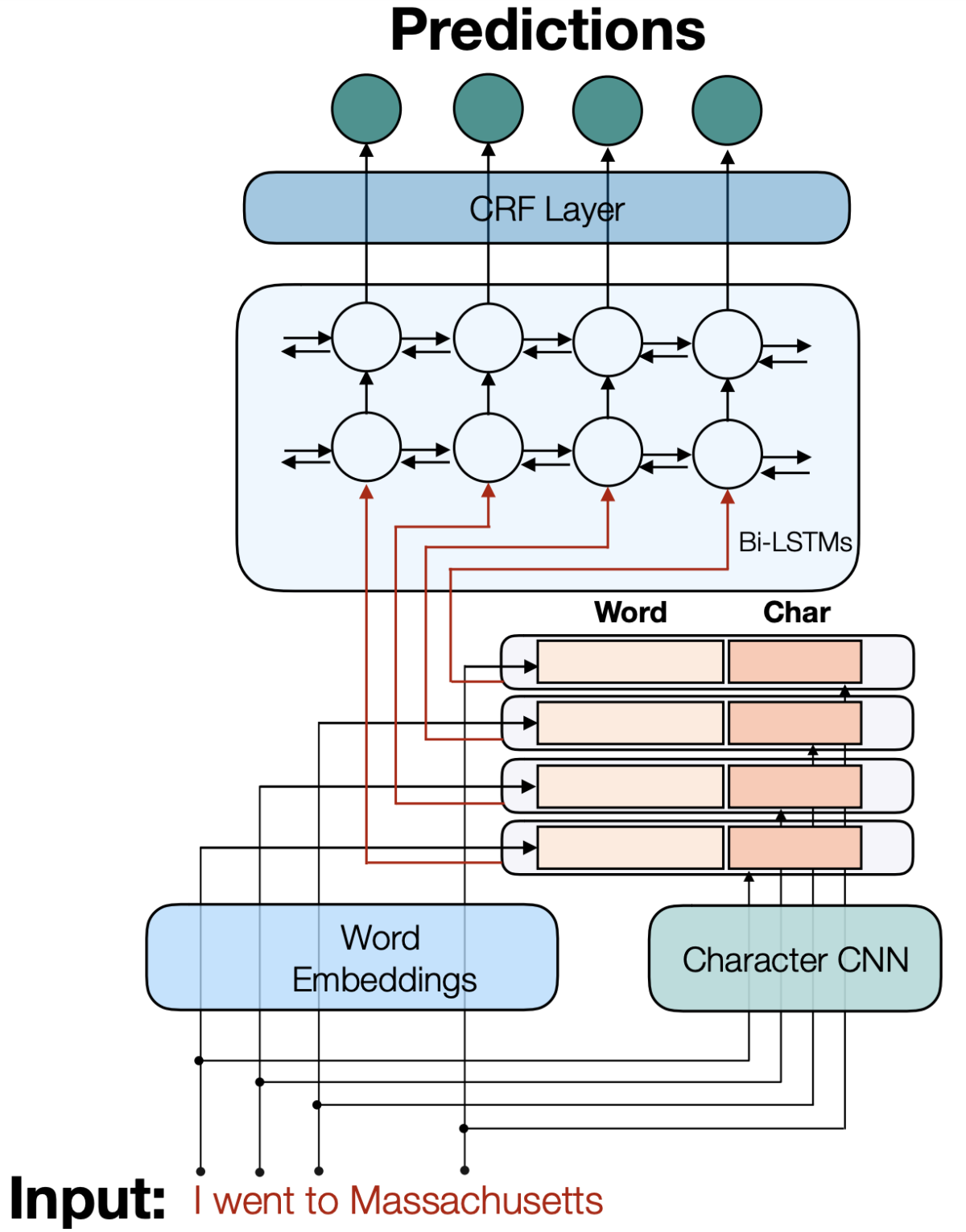
In a paper we presented this week at the annual meeting of the Association for Computational Linguistics, my colleagues and I describe a new way to integrate VAT with conditional random fields
In experiments, we compared our system to its four best-performing predecessors on three different sequence-labeling tasks using semi-supervised learning, in which a small amount of labeled training data is supplemented with a large body of unlabeled data. On eight different data sets, our method outperformed all four baselines across the board.
Conventional adversarial training is a supervised learning technique: noise is added to labeled training examples to make them harder to classify, and the machine learning system is evaluated according to how well it predicts the labels.
VAT extends this approach to semi-supervised learning, which seeks to take advantage of unlabeled data. First, a model is trained on labeled data. Then, noise is added to a large body of unlabeled data, and the model is further trained on how well its classifications of the noisy versions of the unlabeled data match its classifications of the clean versions.
This approach depends on a comparison of aggregate statistics — the classifications of the clean and noisy data. But conditional random fields (CRFs) make that comparison more complicated.
Sequential dependencies
A CRF models the statistical relationships between successive items in a sequence, which is what makes it so useful for sequence-labeling tasks, such as determining parts of speech or identifying the entity types (song, singer, album, and so on) associated with each name in a sequence of words.
For instance, on a named-entity recognition task, a CRF could predict that a word that follows the name of a song is much more likely to be the name of a singer than that of a travel company. In many neural-network-based natural-language-understanding models, the last layer of the network is a CRF, which narrows the range of possible outputs that the model needs to evaluate.
VAT, however, isn’t designed to handle the sequential dependencies captured by CRFs. Consider, for instance, a named-entity recognizer that receives the input sequence “Play ‘Burn’ by Usher”. It should classify “Burn” as a song name and “Usher” as an artist name.
Conventional VAT could attempt to match the classifications of the noisy and clean versions of the word “Burn” and the classifications of the noisy and clean versions of the word “Usher”. But it wouldn’t try to match the statistical dependency learned by the CRF: that if “Burn” is a song name, “Usher” is much more likely to be an artist name than otherwise.
That’s the dependency that we set out to capture with our model, which we call seqVAT, for sequential VAT.
Combinatorial explosion
One way to model that dependency is to calculate the probabilities of complete sequences of labels. That is, there’s some probability that “Burn” is a song name and “Usher” is an artist name, that “Burn” is a song name and “Usher” is an album name, that “Burn” is the name of a restaurant and “Usher” the name of a nearby geographical landmark, and so on.
As the number of entity classes grows, however, enumerating the probability of every possible sequence of classifications rapidly becomes computationally intractable. So instead, we use an algorithm called the k-best Viterbi algorithm to efficiently find a short list (with k items) of the mostly likely label sequences.
From the probabilities of those sequences, we can estimate a probability distribution over the labels of the entire output sequence. We then train the network to minimize the difference between that probability distribution in the case of noisy, unlabeled examples and in the case of clean, unlabeled examples.
In our experiments, in something of a departure from prior practice, we used one data set for the supervised portion of the training and a different but related data set for the semi-supervised portion. This more accurately simulates conditions in which the need for semi-supervised training tends to arise. Often, semi-supervised training is necessary precisely because labeled data is scarce or absent for the target application, although it’s available for related applications.
We compared seqVAT’s performance to that of three popular semi-supervised training approaches — self-training, entropy minimization, and cross-view training — and to that of conventional VAT, which seeks to minimize the distance between probability distributions over individual words in a sequence, rather than distributions over the sequence as a whole.
In the semi-supervised setting, seqVAT was consistently the best performer, while the second-best performer varied between cross-view training and conventional VAT.



