
When people speak, they use different speaking styles depending on context. A TV newscaster, for example, will use a very different style when conveying the day’s headlines than a parent will when reading a bedtime story. Amazon scientists have shown that our latest text-to-speech (TTS) system, which uses a generative neural network, can learn to employ a newscaster style from just a few hours of training data. This advance paves the way for Alexa and other services to adopt different speaking styles in different contexts, improving customer experiences.
To users, synthetic speech produced by neural networks sounds much more natural than speech produced through concatenative methods, which string together short speech snippets stored in an audio database. We present Amazon’s approach to neural TTS (NTTS) in a series of newly released papers:
- Supervised domain enablement attention for personalized domain classification
- Effect of data reduction on sequence-to-sequence neural TTS
- Comprehensive evaluation of statistical speech waveform synthesis
With the increased flexibility provided by NTTS, we can easily vary the speaking style of synthesized speech. For example, by augmenting a large, existing data set of style-neutral recordings with only a few hours of newscaster-style recordings, we have created a news-domain voice. That would have been impossible with previous techniques based on concatenative synthesis.
The examples below provide a comparison of speech synthesized using concatenative synthesis, NTTS with standard neutral style, and NTTS with newscaster style.
Female voice
Male voice
How NTTS can model different speaking styles
Our neural TTS system comprises two components: (1) a neural network that converts a sequence of phonemes — the most basic units of language — into a sequence of “spectrograms,” or snapshots of the energy levels in different frequency bands; and (2) a vocoder, which converts the spectrograms into a continuous audio signal.
The first component of the system is a sequence-to-sequence model, meaning that it doesn’t compute a given output solely from the corresponding input but also considers its position in the sequence of outputs. The spectrograms that the system outputs are mel-spectrograms, meaning that their frequency bands are chosen to emphasize acoustic features that the human brain uses when processing speech.
When trained on the large data sets used to build general-purpose concatenative-synthesis systems, this sequence-to-sequence approach will yield high-quality, neutral-sounding voices. By design, those data sets lack the distinctive prosodic features required to represent particular speech styles. Although high in quality, the speech generated through this approach displays a limited variety of expression (pitch, breaks, rhythm).
On the other hand, producing a similar-sized data set by enlisting voice talent to read in the desired style is very time consuming and expensive. (Training a sequence-to-sequence model from scratch requires tens of hours of speech).
We find that we can leverage a large corpus of style-neutral data in the training of a style-specific speech synthesizer by making a simple modification to the sequence-to-sequence model. We train the model not only with phoneme sequences and the corresponding sequences of mel-spectrograms but with a “style encoding” that identifies the speaking style employed in the training example.
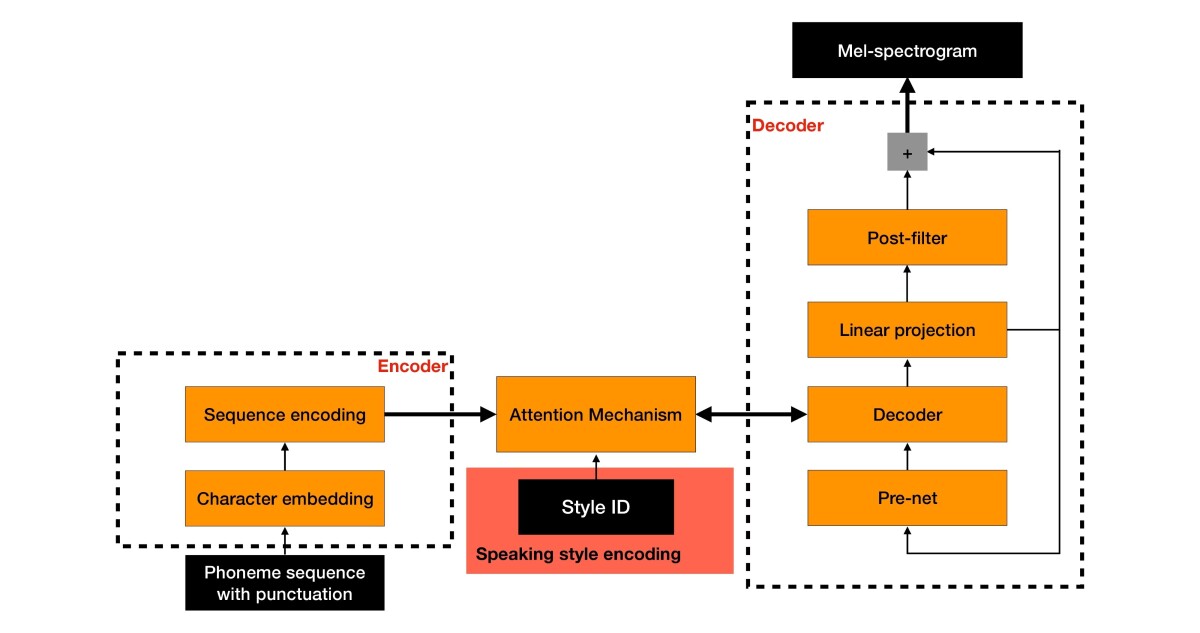
With this approach, we can train a high-quality multiple-style sequence-to-sequence model by combining the larger amount of neutral-style speech data with just a few hours of supplementary data in the desired style. This is possible even when using an extremely simple style encoding, such as a “one-hot” vector — a string of zeroes with a single one at the location corresponding to the selected style.
The key technical advantage of this multiple-style sequence-to-sequence model is its ability to separately model aspects of speech that are independent of speaking style and aspects of speech that are particular to a single speaking style. When presented with a speaking-style code during operation, the network predicts the prosodic pattern suitable for that style and applies it to a separately generated, style-agnostic representation. The high quality achieved with relatively little additional training data allows for rapid expansion of speaking styles.
The output of our model passes to a neural vocoder, a neural network trained to convert mel-spectrograms into speech waveforms. In order to be of general practical use, the vocoder must be capable of simulating speech by any speaker in any language in any speaking style. Typically, neural vocoder systems use some form of speaker encoding (either a one-hot encoding or some other vector representation, or “embedding”). Our neural vocoder takes mel-spectrograms from any speaker, regardless of whether he or she was seen during training time, and generates high-quality speech waveforms without the use of a speaker encoding.
Listener perception of style
To determine whether the NTTS newscaster style makes a difference to listeners’ experiences, we conducted a large-scale perceptual test. We asked listeners to rate speech samples on a scale from 0 to 100, according to how suitable their speaking styles were for news reading. We included an audio recording of a real newscaster as a reference.
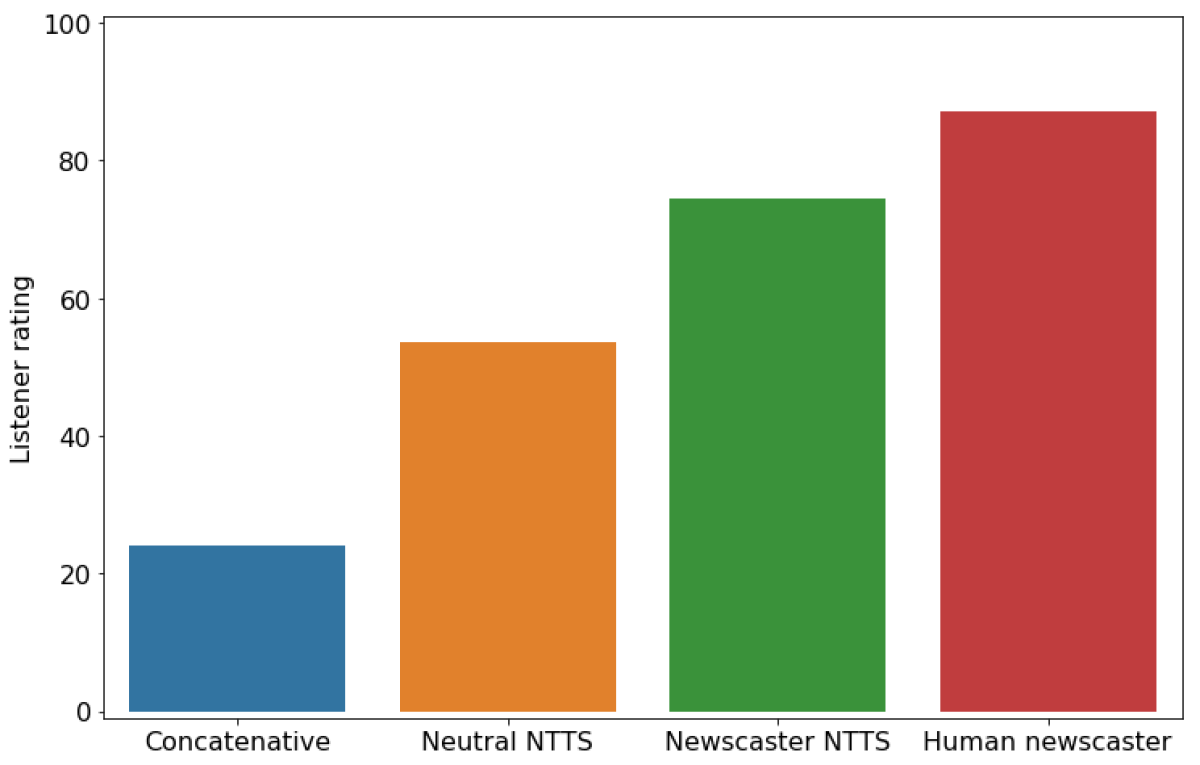
The results are presented in the figure below. Listeners rated neutral NTTS more highly than concatenative synthesis, reducing the score discrepancy between human and synthetic speech by 46%. They preferred NTTS newscaster style to both other systems, however, shrinking the discrepancy by a further 35%. The preference for the neutral-style NTTS reflects the widely reported increase in general speech synthesis quality due to neural generative methods. The further improvement for the NTTS newscaster voice reflects our system’s ability to capture a style relevant to the text.
Acknowledgments: Adam Nadolski, Roberto Barra-Chicote, Jaime Lorenzo Trueba, Srikanth Ronanki, Viacheslav Klimkov, Nishant Prateek, Vatsal Aggarwal, Alexis Moinet



