
Amazon has strong ties to the Web Search and Data Mining (WSDM) conference, which starts next week in Houston. Amazon is a gold sponsor of the conference, and seven Amazon scientists are members of various conference committees.

Yoelle Maarek, vice president of research and science for Alexa Shopping, is not only a member of the WSDM steering committee; she was also there when the conference was established.
“I had been part of The Web Conference [formerly WWW] community since its early days in ’93, ’94,” Maarek says. “I remember in the early 2000s that among the multiple tracks of the conference, there were two tracks, namely search and data mining, that were totally swamped by submissions. A few of us in the community were frustrated because the field was progressing so fast, there was so much demand for research in that area, that we had the feeling that these two tracks were overpopulated, cramped, and there was tons of good work that could not be featured.”
“So we consulted with the president of the ACM [the Association for Computing Machinery] at the time, Stu Feldman,” Maarek continues. “Stu told us, ‘You know what? You should simply create a new conference. There’s room for that.’ And as happens quite often with Stu, he was right! A new conference series, WSDM, was created in 2008.”
By the standards of the large machine learning conferences, WSDM (pronounced “wisdom”) is still relatively small: this is the first year that it will feature two parallel talk tracks, so that one conferencegoer can no longer attend all the paper presentations. But it has become extraordinarily selective, accepting only 15% of paper submissions this year.
“It just shows the quality of the conference,” Maarek says. “Usually a top-tier conference is at 20% acceptance.”
“If you want something that would characterize WSDM, it’s really about using large-scale, principled methods,” Maarek says. “‘Principled’ is very important: it has to be rooted in theory — very, very rigorous math. But it has to scale to the scale of the web. There are other conferences where you can do a user study of 20 users. When you talk about WSDM, the scale should be in the hundreds of thousands, if not in the millions.”
The conference organizers also “want to see research innovation, something fresh and inspiring,” Maarek says. “But freshness can be either in the statement of the problem or in the method. It doesn’t need to be systematically in the method. It could also be a new problem that people didn’t think of looking at and a way to get new signals. So it’s not just a way of advancing the pure ML part — there are other conferences focused on this — and it goes very well with our concept of customer-obsessed science, where we want to find new ways to satisfy and delight customers.”
“With WSDM we have the chance to connect with a small, vibrant community,” Maarek adds. “It’s still intimate, like a ‘boutique conference’. There are still a ton of plenary sessions for people to mingle and talk to each other. That’s a really important thing, that community.”
Amazon researchers have four papers at WSDM this year (Maarek is a coauthor on one of them), which span a wide range of topics:
“AutoBlock: A Hands-off Blocking Framework for Entity Matching”
Hao Wei, Xin Luna Dong, Bunyamin Sisman, Wei Zhang, Christos Faloutsos, David Page
Removing duplicate data entries is a key step in linking data from multiple sources, and only a scalable solution can enable applications such as building large-scale knowledge graphs. The first step in searching a large database for duplicate entries is “blocking”, or finding a subset of likely duplicates; otherwise, the search could be prohibitively time consuming. Usually, blocking is the result of handcrafted search queries, but this paper proposes an automated blocking technique. The key is embedding, or mapping textual data into a geometric space, such that similar text strings cluster together. The researchers present an efficient algorithm for searching that space, so their automatic-blocking technique can easily handle databases with millions of records.
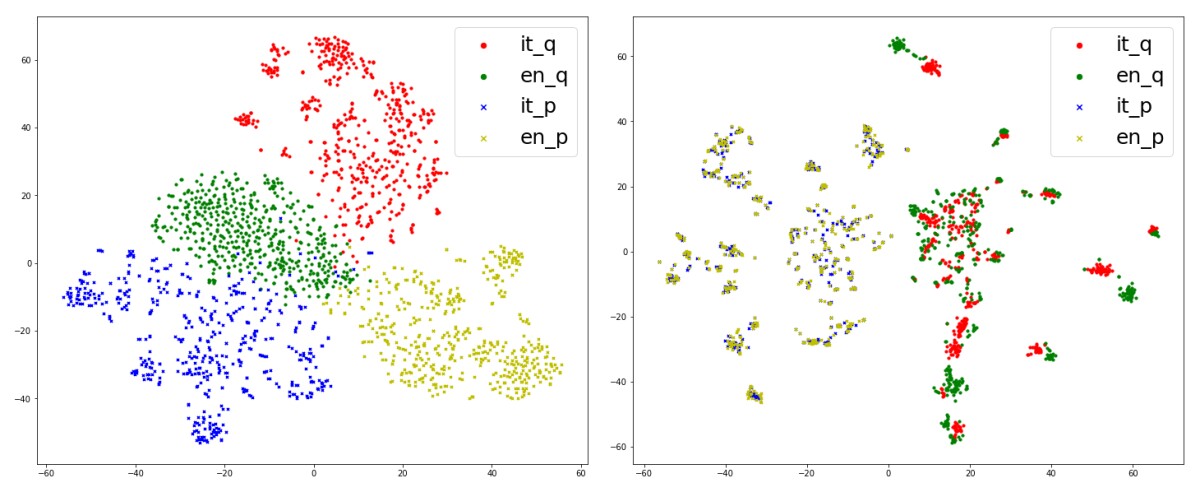
“Language-Agnostic Representation Learning for Product Search on E-Commerce Platforms”
Aman Ahuja, Nikhil Rao, Sumeet Katariya, Chandan Reddy, Karthik Subbian
Amazon’s online-shopping experience is available in many languages, but customers in different countries are often looking for the same products. In this paper, Amazon researchers show that training a single machine learning model on data in many different languages improves performance in all of them. A key to the system is mapping descriptions of the same products and customer queries to the same regions of a representational space, regardless of language of origin.
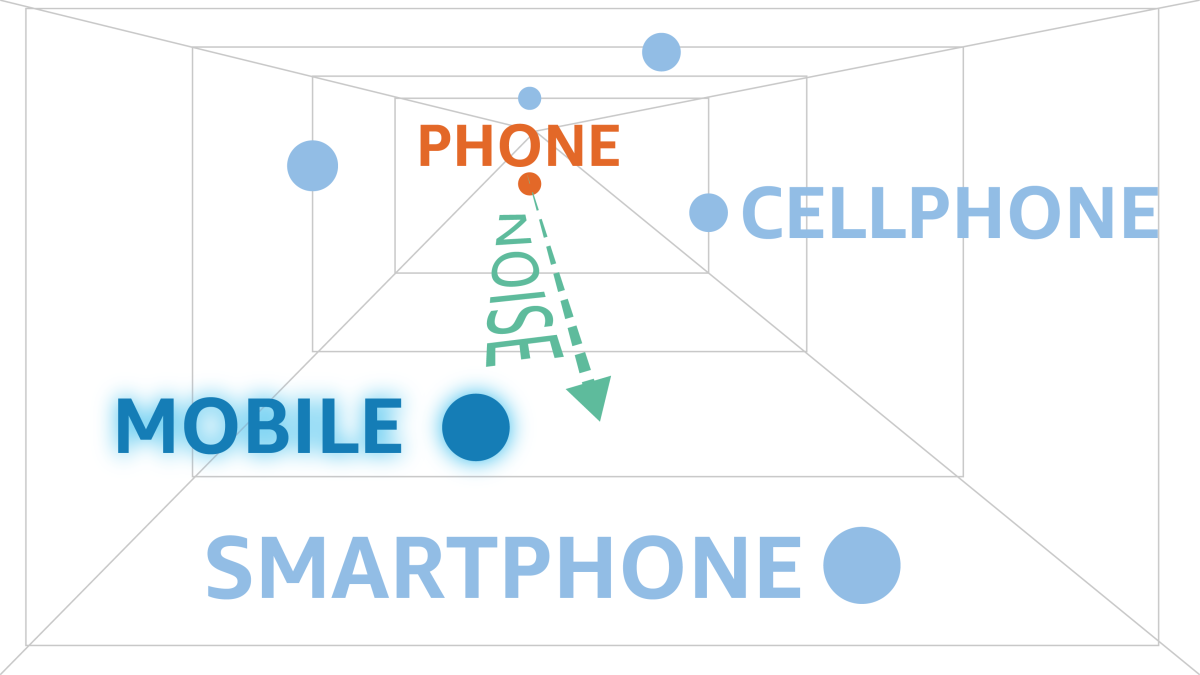
“Privacy- and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations”
Oluwaseyi Feyisetan, Borja Balle, Thomas Drake, Tom Diethe
Differential privacy is a framework for evaluating the privacy risks associated with the public release of data. It can offer probabilistic assurances that aggregate statistics about a data set will not leak information about individuals included in the data set. This paper uses a variation on differential privacy, called metric differential privacy, to offer similar assurances about data sets consisting of transcribed speech. The researchers designed a system that replaces words in each transcribed utterance with semantically related words, producing rephrases that reduce the likelihood of privacy leaks while still enabling useful analysis. Blog post here.
“Why Do People Buy Seemingly Irrelevant Items in Voice Product Search?”
David Carmel, Elad Haramaty, Arnon Lazerson, Liane Lewin-Eytan, Yoelle Maarek
If a customer says to Alexa “buy burgers”, is a stuffed-burger press a relevant product? Human annotators say no, but some customers who issued that request in fact bought the burger press. This paper provides a detailed statistical analysis of cases in which voice search customers bought seemingly irrelevant items, with suggestions for improving product discovery models.



