
Transfer learning is a widely used technique for improving the performance of neural networks when labeled training data is scarce. Before a network is trained on a target task with limited data, it might be pretrained on a source task with more abundant data. The knowledge it gains from pretraining would then be transferred to the target task.
When is transfer learning effective, and when is it not? And if you’re going to do transfer learning, what task should you use for pretraining? Answering these and related questions is the aim of transferability metrics, which measure the applicability of a pretrained network to new tasks.
At this year’s International Conference on Machine Learning, my colleagues and I are presenting a new transferability metric, which in our experiments proved to be a better predictor of transferability than existing metrics.
It’s also more general than existing metrics: it’s theoretically grounded and does not make strong assumptions about the relatedness of source and target tasks, as previous metrics often do.
In the paper, we offer theoretical analyses indicating that our metric — which we call LEEP, for log expected empirical prediction — should offer a good estimate of transferability.
We also conducted a battery of empirical tests, comparing our metric to its two leading predecessors in 23 different transfer settings, which combined three types of transfer learning, two image recognition source tasks, and target tasks that involved different subsets of the training data for two further image recognition tasks.
On 15 of those 23 comparisons, LEEP’s predictions correlated better than those of the other two metrics with the ultimate accuracy of the transferred model. In some cases, the difference was dramatic — an improvement of as much as 30% over the second-best metric.
As can be seen from the graphs below, which show our results for two different source data sets, LEEP correlates very well with the ultimate accuracy of the transferred model.
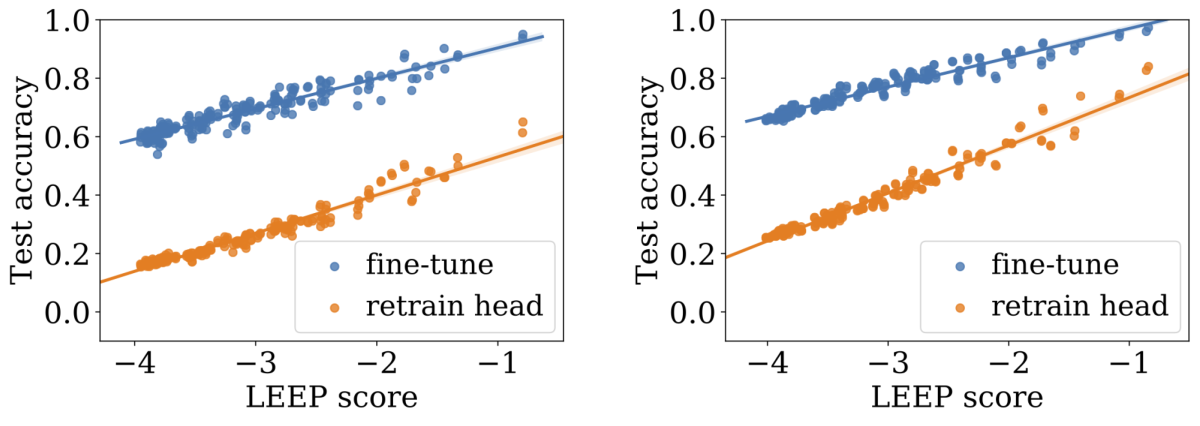
One of the settings we considered was that of meta-transfer learning, which is a combination of transfer learning and meta-learning. With meta-transfer learning, a single deep-learning model is adapted to many new tasks during training, so that it learns to adapt to unseen tasks with very little data.
On that task, LEEP’s correlation with ultimate model accuracy was .591, while the other methods’ correlations were .310 and .025. We believe that LEEP is the first transferability metric that applies to meta-transfer learning.
How do we compute LEEP?
LEEP measures the transferability between a trained machine learning model and the labeled data set for a new task. Suppose, for instance, that the model has been trained to recognize images of land animals, and the target task is to recognize sea animals.
The first step in the LEEP process is to use the trained model to classify the data in the training set for the target task. The resulting classifications are dummy labels: the land animal classifier might, for instance, recognize seals as dogs and seahorses as giraffes. But that doesn’t matter for purposes of transferability prediction.
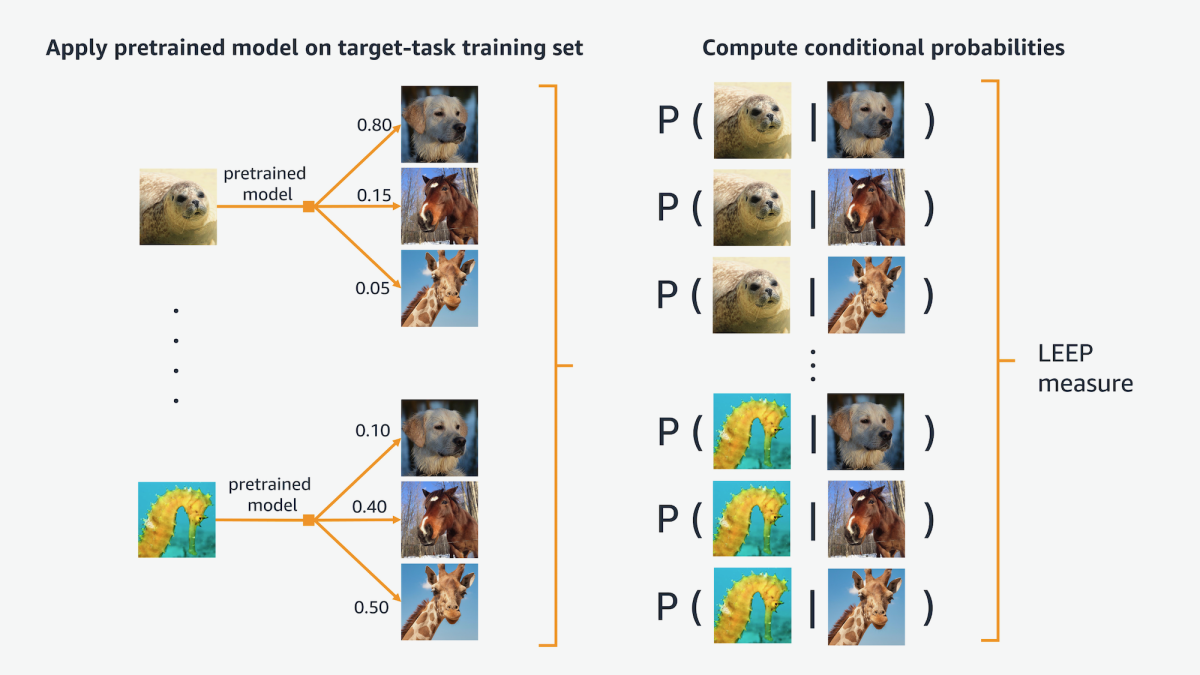
For every example in the training set, we have the correct label, so the next step is to compute the conditional probabilities of target-task labels given the dummy classifications of the trained model — the probability that an example classified as a dog is actually a seal, a seahorse, a shark, and so on.
Finally, we imagine a classifier that will, according to that conditional distribution, randomly pick a dummy label for each input and, on the basis of that dummy label, randomly pick a target-task label.
LEEP is the average log-likelihood of this hypothetical classifier on the data in the target-task training set. Log-likelihood is a standard measure of how well a statistical model fits a particular collection of data samples, so LEEP tells us how well the hypothetical classifier fits the target-task training set. That makes it an easy-to-interpret as well as accurate metric.
Potential applications of LEEP
We believe that LEEP has several potential applications.
First, it can be used to select source models for transfer learning. It could also help select groups of highly transferable tasks for multitask learning, in which a single machine learning model is trained on several tasks at once.
LEEP could also be useful for the transfer and optimization of hyperparameters, which are structural features of machine learning models or parameters of learning algorithms that help maximize the efficacy of training on particular data.



