
This Sunday's Super Bowl between the New England Patriots and the Los Angeles Rams is expected to draw more than 100 million viewers, some of whom will have Alexa-enabled devices within range of their TV speakers. When Amazon's new Alexa ad airs, and Forest Whitaker asks his Alexa-enabled electric toothbrush to play his podcast, how will we prevent viewers’ devices from mistakenly waking up?

With the Super Bowl ad — as with thousands of other media mentions of Alexa tracked by our team — we teach Alexa what individual recorded instances of her name sound like, so she will know to ignore them. We can also apply this technique, known as acoustic fingerprinting, on the fly to recognize when multiple devices from different households are hearing the same command at around the same time. This is crucial to preventing Alexa from responding to pranks on TV, references to people named Alexa, or other instances of her name in broadcast media that we don't know about in advance.

Our approach to matching audio recordings is based on classic acoustic-fingerprinting algorithms like that of Haitsma and Kalker in their 2002 paper “A Highly Robust Audio Fingerprinting System”. Such algorithms are designed to be robust to audio distortion and interference, such as those introduced by TV speakers, the home environment, and our microphones.
To produce an acoustic fingerprint, we first derive a grid of log filter-bank energies (LFBEs) for the acoustic signal, which represent the amounts of energy in multiple overlapping frequency bands in a series of overlapping time windows. The algorithm steps through the grid in two-by-two blocks and adds and subtracts the measurements in the grid cells in a standardized way. (Technically, it computes the 2-D gradient of each block.) The sign of the result — positive or negative — provides a one-bit summary of the values in the block. The summaries of all the blocks in the grid constitute the acoustic fingerprint, and two fingerprints are deemed to match if the fraction of bits that are different (the “bit error rate”) is small enough.
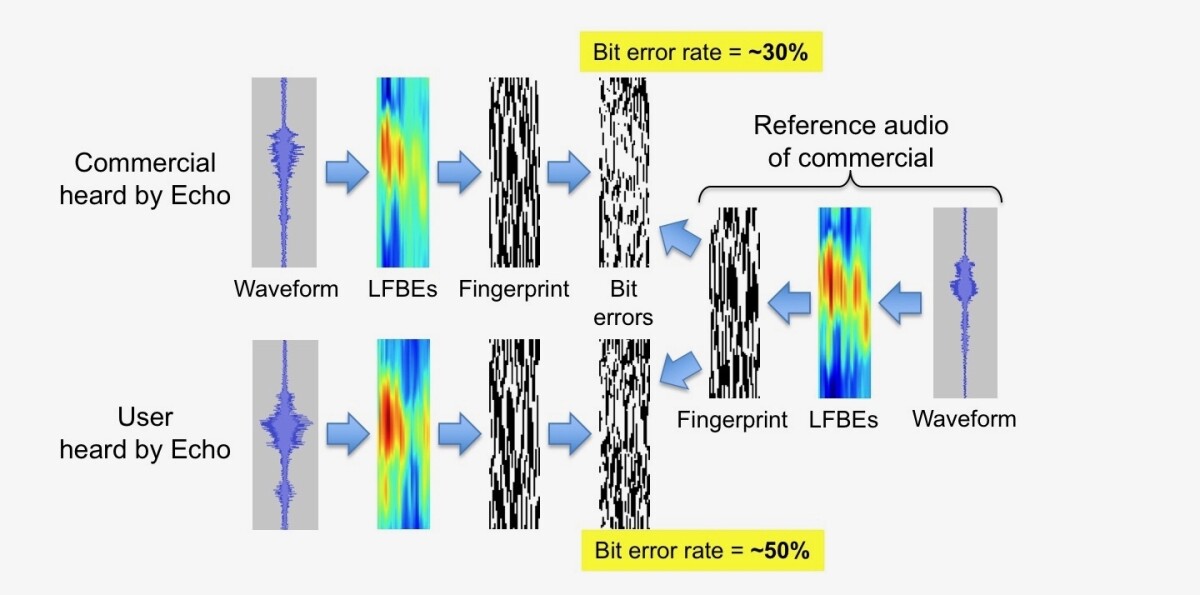
When we have audio samples in advance — as we do with the Super Bowl ad — we fingerprint the entire sample and store the result. With audio that’s streaming to the cloud from Alexa-enabled devices, we build up fingerprints piecemeal, repeatedly comparing them to other fingerprints as they grow.
If a match is found, the incoming request is ignored. Noisy audio may yield a match, but it requires the accumulation of more data (a larger fingerprint) than clean audio does.
Using this matching algorithm, we have built a system with multiple layers to protect customers at multiple stages:
- On-device: On most Echo devices, every time the wake word “Alexa” is detected, the audio is checked against a small set of known instances where Alexa is mentioned in commercials. Due to the limits of device CPU, this set is generally restricted to commercials we expect to be currently airing on TV.
- In the cloud: Every audio request to Alexa that starts with a wake word is checked in two ways:
- Known media: the audio is checked against a large set of fingerprints for known instances of “Alexa” and other wake words in commercials and other media. These fingerprints can also make use of the audio that follows the wake word.
- Unknown media: the audio is checked against a fraction of other Alexa requests arriving at around the same time. If the audio of a request matches that of requests from at least two other customers, we identify it as a media event. We also check incoming audio against a small cache of fingerprints discovered on the fly (the cached fingerprints are averages of the fingerprints that were declared matches). The cache allows Alexa to continue to ignore spurious wake words even when they no longer occur simultaneously.
Ideally, a device will identify media audio using locally stored fingerprints, so it does not wake up at all. If it does wake up, and we match the media event in the cloud, the device will quickly and quietly turn back off.
In addition to tracking new media mentions of Alexa’s name and updating our library of fingerprints accordingly, our team works continuously to improve the accuracy and efficiency of the fingerprinting system. We’re also exploring complementary technologies, such as machine learning systems that can distinguish media audio more generally from live human speech.
Acknowledgments: Joe Wang, Aaron Challenner, Mike Peterson, Michael Rudeen, Naresh Narayanan, Liangwei Guo, and the rest of the team



