

Many popular AI applications — such as machine translation, conversational AI, and question answering — depend on natural-language generation, or producing new sequences of syntactically and semantically coherent text.
Sometimes it’s useful to modulate the output of a language generator: on different occasions, for instance, a machine translation model might need to produce translations that are more formal or more idiomatic; a conversational-AI model might focus more on delivering information or on eliciting responses from a human interlocutor.
Typically, building natural-language-generation (NLG) models that provide this kind of control means re-training them on the appropriate type of annotated data — formal or informal diction, informative or interrogative utterances. But researchers in the Alexa AI organization have invented a method for modulating a language generator’s output without the need for re-training.
Instead, they’ve added what they describe as three “control knobs” to an NLG model, which can vary the model output. They describe their approach in a paper called “Zero-shot controlled generation with encoder-decoder transformers”, which they’ve posted to the arXiv. The paper’s corresponding author, senior applied scientist Mahdi Namazifar, answered 3 questions about his team’s work for Amazon Science.
Q. What does it mean to add a “control knob” to an NLG model?
The general belief in this area is that once you have a trained model, if you go into it and make changes manually, that causes it to degenerate. Contrary to this belief, one of the things that we do in this work is exactly that: we take a trained model and manually manipulate the weights of the model, the parameters of the model. And we show that not only does it not cause degeneration of the model — we see that we can maintain the quality of the generations — but you achieve control by doing this, if you do it in a systematic way and an intuitive way.
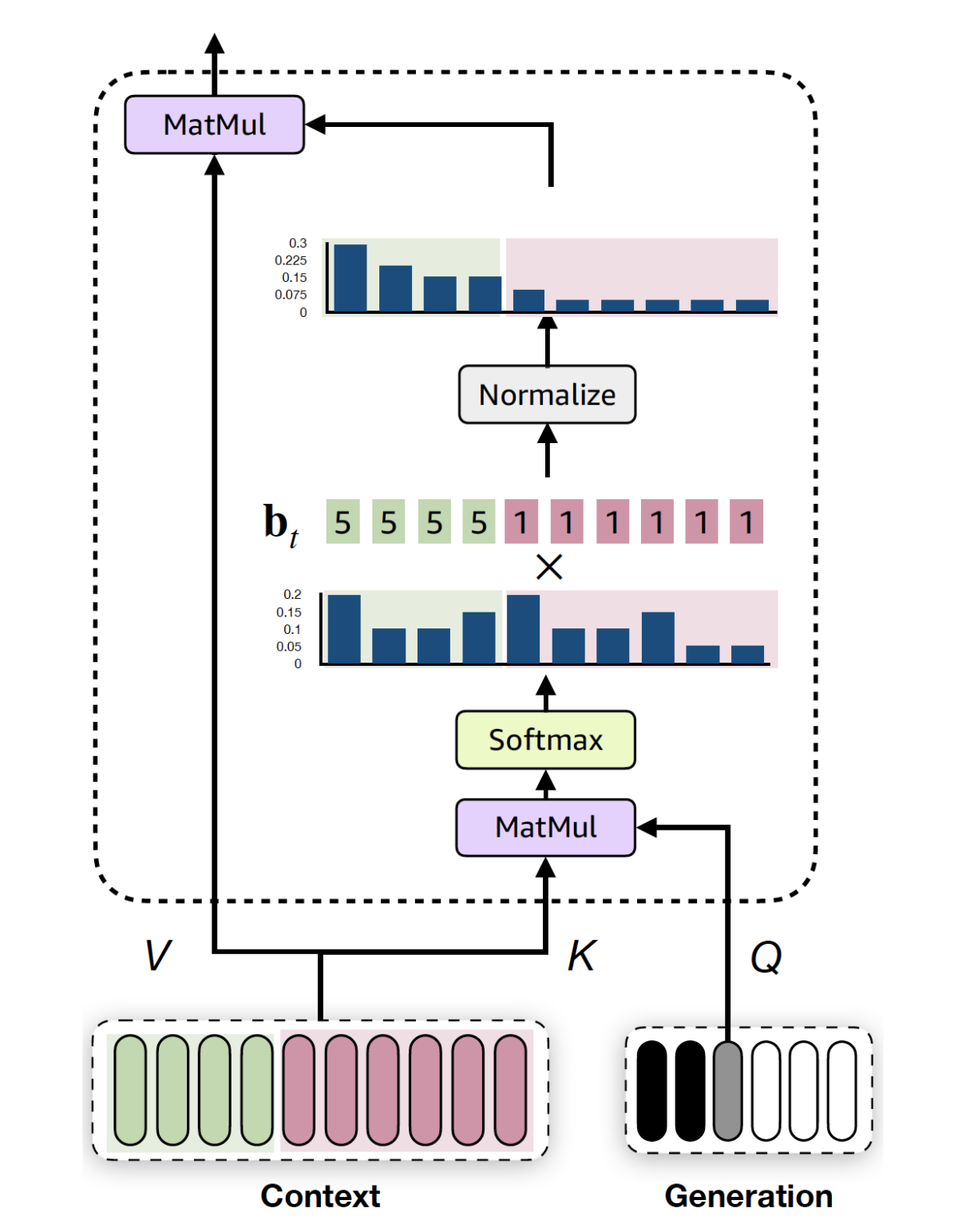
A good example of that is attention biasing. The attention mechanism makes a decision that at this point I need to pay attention, in this distribution, to the input. We show that we can go into the attention modules and force the trained model to pay more attention to certain parts of the context than it usually would.
For instance, if you have a dialogue model, and we want the next response to the user to be more informative, we can actually force the model to pay more attention to the knowledge snippet that we’ve provided. And again, the expectation would be this would throw off the model completely, but we saw — very surprisingly — that that doesn't happen, and in fact it achieves what we had in mind, and it follows the intuition.
Q. What are the other two knobs?
Another knob we introduce here is decoder mixing. Imagine you have two different models that have two different decoders, and these decoders have learned different skills. So, for instance, in a conversation and a dialogue system, the decoder has learned, given the dialogue history, how to respond. And imagine a different decoder with a completely different task — for instance, an autoencoder, which, given an encoding of the input, is able to reconstruct the input. So, these two decoders have learned different skills. We show that by mixing them, we can mix the skills that they have learned. This one can respond; this one can copy from the input. If you have, for instance, some knowledge within the input, then combining these allows us to have a response that is more informative.
The third knob is another interesting one. To get to certain desired controls, what we propose here is to augment the input with certain additional input — which, again, is intuitively designed. For instance, if you want the generated language to be a question, we show that if we get a bunch of questions, and we encode them in a certain way, and we augment our input with this encoding of the questions, the model is able to generate more questions; whatever the model wanted to generate, it generates it in a question manner. Or if you wanted to generate according to a certain topic, you would give it control phrases in that topic, and it would push the model to generate according to that topic, or with a certain sentiment, and so on.
This is kind of similar to the concept of priming of language models that is out there in the literature, but priming was never shown to work for smaller language models. It was shown to work for language models with hundreds of billions of parameters, which are very computationally expensive to run. But we show that this version of “priming” could allow much, much smaller models — three orders of magnitude smaller models, even — to use this notion of priming in a different way. And again, this knob and the other two need absolutely no additional training and annotated data.
Q. Did you experiment with any other types of control knobs?
Encoder-decoder Transformer-based NLG models have two sets of attentions. One is called self-attention, and one is called cross-attention. Self-attention gets kicked in as the model is generating, and it attends to what it has generated up to this point — “what was the word that came out of my mouth two seconds ago?” Cross-attention pays attention to the context — everything that was said last turn, or some sort of knowledge about the topic of the conversation, and so on. We saw that applying attention biasing on cross-attention worked very well, as is discussed in the paper, but when we apply attention biasing to self-attention, we see basically what we were expecting from the get-go, which was the model starting to generate gibberish, basically, or the models starting to degenerate.

After a lot of digging into this, we propose — basically, as a hypothesis — that in these models, this self-attention module is responsible for the fluency of the generated language, and probably that's its main function. So why is this important? We show that if we have another model that is fluent, and we replace this part of the model with another fluent model, we still get good generations. What that tells us is maybe we don't need to focus on training these when we're training a model for whatever task we have. If we have a model that generates fluently, we can just use those weights and modules.
The benefit of doing that is basically savings in computations. We see that in some cases, we can train the model with 44% fewer weights and parameters and still get pretty competitive numbers, which is very important, because training these models is very expensive. Training time would be reduced significantly, and we can use smaller machines for training the same model, which also reduces the carbon footprint.
That's a secondary kind of contribution of this work, which is focusing on a case where it didn't work. This knob didn't work, and when we dug into why it didn't work, we came to some new findings.



