
Automatic speech recognition (ASR) is the conversion of acoustic speech to text, and with Alexa, the core ASR model for any given language is the same across customers.
But one of the ways the Alexa AI team improves ASR accuracy is by adapting models, on the fly, to customer context. For instance, Alexa can use acoustic properties of the speaker’s voice during the utterance of the wake word “Alexa” to filter out background voices when processing the customer’s request.

Alexa can also use the device context to improve performance. For instance, a device with a screen might display a list of possible responses to a query, and Alexa can bias the ASR model toward the list entries when processing subsequent instructions.
Recently, Alexa also introduced a context embedding service, which uses a large neural network trained on a variety of tasks to produce a running sequence of vector representations — or embeddings — of the past several rounds of dialogue, both the customer’s utterances and Alexa’s responses.
The context embeddings are an on-tap resource for any Alexa machine learning model, and the service can be expanded to include other types of contextual information, such as device type, customers’ skill and content preferences, and the like.
Theory into practice
At Amazon Science, we report regularly on the machine learning models — including those that use context — that enable improvements to Alexa’s speech recognizer. But rarely do we discuss the engineering effort required to bring those models into production.
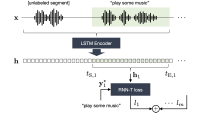
To get a sense for the scale of that effort, consider just one of Alexa’s deployed context-aware ASR models, which uses conversational context to improve accuracy when Alexa asks follow-up questions to confirm its understanding of commands. For instance:
Customer: “Alexa, call Meg.”
Alexa: “Do you mean Meg Jones or Meg Bauer?”
Customer: “Bauer.”
When Alexa hears “Bauer” in the second dialogue turn, it favors the interpretation “Bauer” over the more common “power” based on the context of the previous turn. On its initial deployment, conversational-context awareness reduced the ASR error rate during such interactions by almost 26%.
The underlying machine learning model factors in the current customer utterance, the text of the previous dialogue turn (both the customer’s utterance and Alexa’s response), and relevant context information from the Alexa services invoked by the utterance. This might include entries from an address book, a list of smart-home devices connected to Alexa, or the local-search function’s classification of names the customer mentioned — names of restaurants, of movie theaters, of gas stations, and so on.
But once the model has been trained, the engineers’ work is just beginning.
Problems of scale
The first engineering problem is that there’s no way to know in advance which interactions with Alexa will require follow-up questions and responses. Embedding context information is a computationally intensive process. It would be a waste of resources to subject all customer utterances to that process, when only a fraction of them might lead to multiturn interactions.
Instead, Alexa temporarily stores relevant context information on a server; utterances are time stamped and are automatically deleted after a fixed span of time. Only utterances that elicit follow-up questions from Alexa pass to the context embedding model.

For storage, the Alexa engineers are currently using AWS’s DynamoDB service. Like all of AWS’s storage options, DynamoDB encrypts the data it stores, so updating an entry in a DynamoDB table requires decrypting it first.
The engineering team wanted to track multiple dialogue events using only a single table entry; that way, it would be possible to decide whether or when to begin a contextual embedding with a single read operation.
If the contextual data were stored in the same entry, however, it would have to be decrypted and re-encrypted with every update about the interaction. Repeated for every customer utterance and Alexa reply every day, that would begin to add up, hogging system resources and causing delays.

Instead, the Alexa engineers use a two-table system to store contextual information. One table records the system-level events associated with a particular Alexa interaction, such as the instruction to transcribe the customer’s utterance and the instruction to synthesize Alexa’s reply. Each of these events is represented by a single short text string, in a single table entry.
The entry also contains references to a second table, which stores the encrypted texts of the customer utterance, Alexa’s reply, and any other contextual data. Each of those data items has its own entry, so once it’s written, it doesn’t need to be decrypted until Alexa has decided to create a context vector for the associated transaction.
“We have tried to keep the database design simple and flexible,” says Kyle Goehner, who led the engineering effort behind the follow-up contextual feature. “Even at the scale of Alexa, science is constantly evolving and our systems need to be easy to understand and adapt.”
Computation window
Delaying the creation of the context vector until the necessity arises poses a challenge, however, as it requires the execution of a complex computation in the middle of a customer’s interaction with Alexa. The engineers’ solution was to hide the computation time under Alexa’s reply to the customer’s request.
All Alexa interactions are initiated by a customer utterance, and almost all customer utterances elicit replies from Alexa. The event that triggers the creation of the context vector is re-opening the microphone to listen for a reply.
The texts of Alexa’s replies are available to the context model before Alexa actually speaks them, and the instruction to reopen the microphone follows immediately upon the instruction to begin the reply. This gives Alexa a narrow window of opportunity in which to produce the context vector.
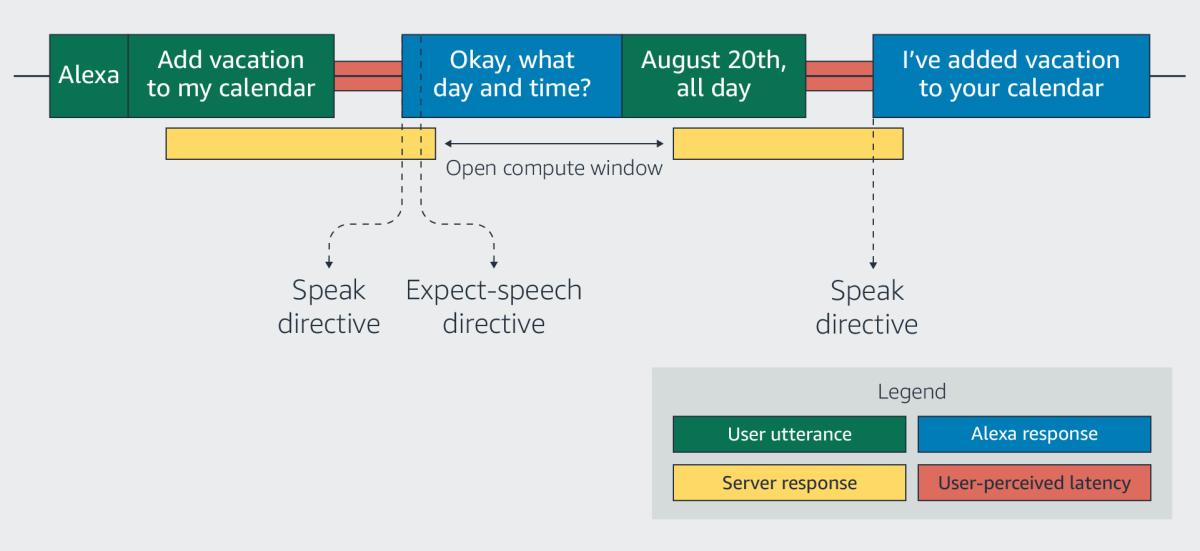
If the context model fails to generate a context vector in the available time, the ASR model simply operates as it normally would, without contextual information. As Goehner puts it, the contextual-ASR model is a “best-effort” model. “We’re trying to introduce accuracy improvement without introducing possible points of failure,” he says.
Consistent reads
To ensure that contextual ASR can work in real time, the Alexa engineers also took advantage of some of DynamoDB’s special features.
Like all good database systems, DynamoDB uses redundancy to ensure data availability; any data written to a DynamoDB server is copied multiple times. If the database is facing heavy demand, however, then when new data is written, there can be a delay in updating the copies. Consequently, a read request that gets routed to one of the copies may sometimes retrieve data that’s out of date.
To guard against this, every time Alexa writes new information to the contextual-ASR data table, it simultaneously requests the updated version of the entry recording the status of the interaction, ensuring that it never gets stale information. If the entry includes a record of the all-important instruction to re-open the microphone, Alexa initiates the creation of the contextual vector; if it doesn’t, Alexa simply discards the data.

“This work is the culmination of very close collaboration between scientists and engineers to design contextual machine learning to operate at Alexa scale,” says Debprakash Patnaik, a software development manager who leads the engineering teams behind the new system.
“We launched this service for US English language and saw promising improvements in speech recognition errors,” says Rumit Sehlot, a software development manager at Amazon. “We also made it very easy to experiment with other contextual signals offline to see whether the new context is relevant. One recent success story has been adding the context of local information — for example, when a customer asks about nearby coffee shops and later requests driving directions to one of them.”
“We recognize that after we’ve built and tested our models, the work of bringing those models to our customers has just begun,” adds Ivan Bulyko, an applied-science manager for Alexa Speech. “It takes sound design to make these services at scale, and that’s something the Alexa engineering team reliably provides.”



