In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift, the first fully managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.

This cloud service was a significant leap from the traditional on-premise data warehousing solutions, which were expensive, not elastic, and required significant expertise to tune and operate. Customers embraced Amazon Redshift and it became the fastest growing service in AWS. Today, tens of thousands of customers use Redshift in AWS’s global infrastructure to process exabytes of data daily.
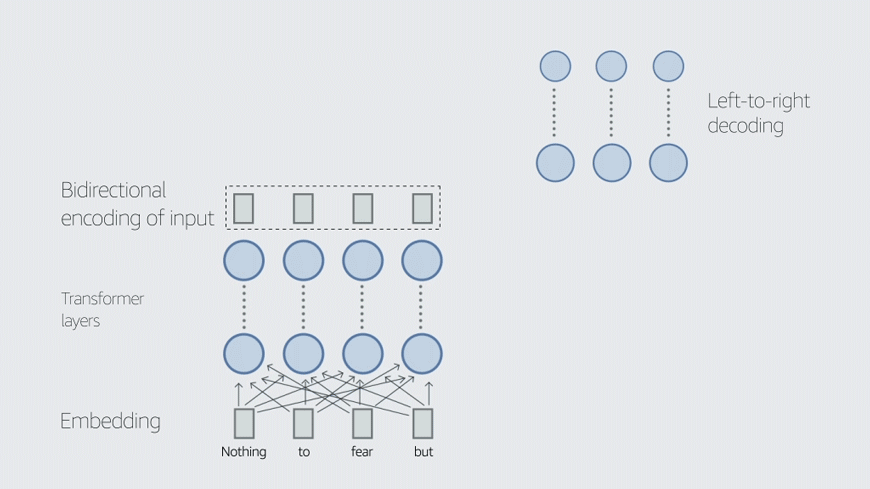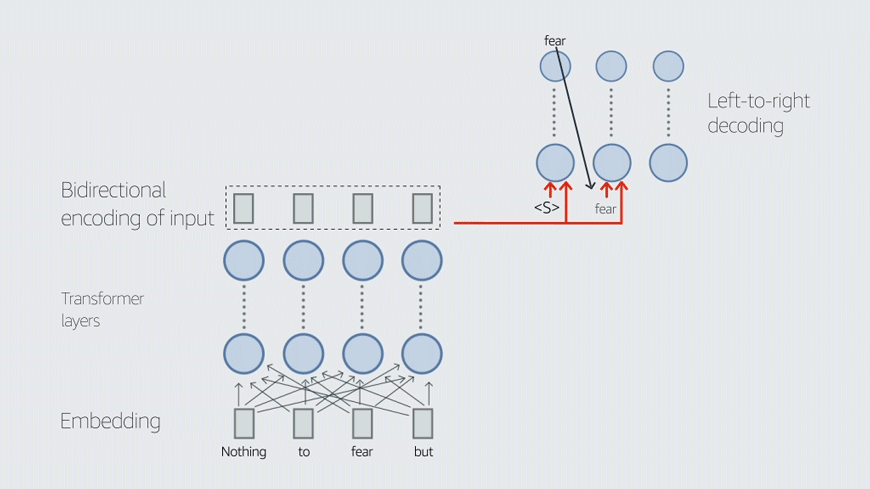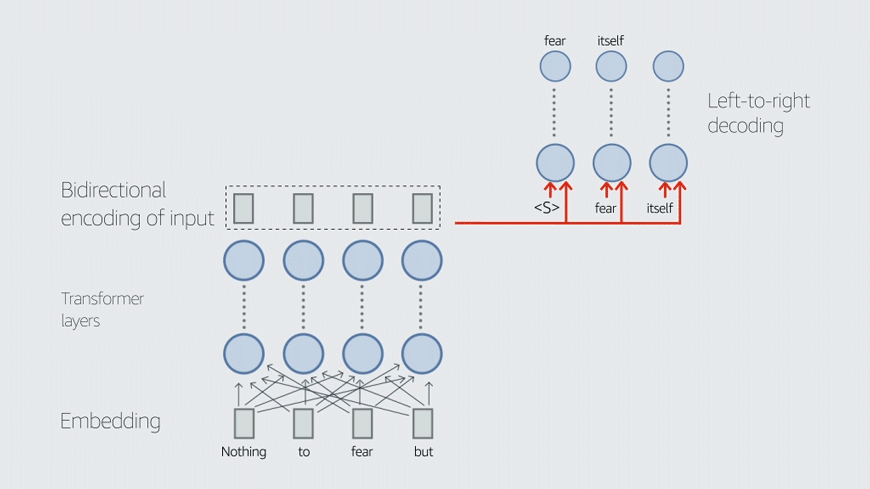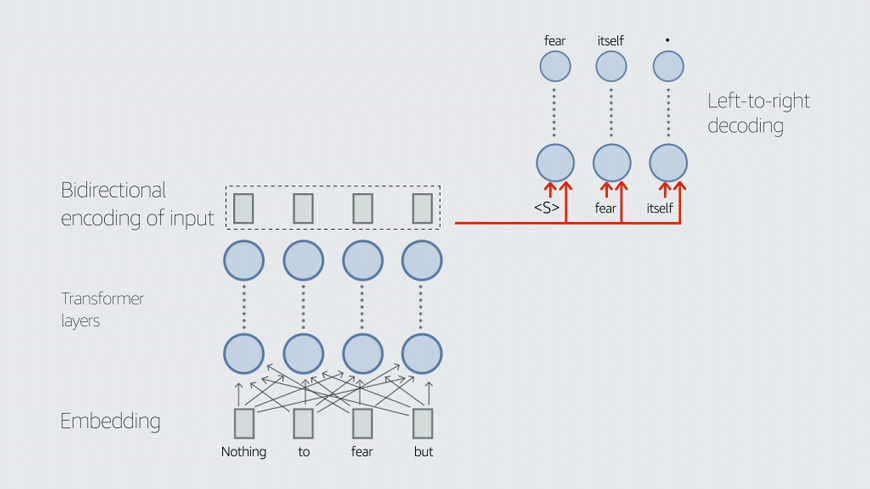
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on one-shot summarization tasks, outperforming a much larger 540B PaLM decoder model.
AlexaTM 20B also achieves SOTA in one-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Amazon DynamoDB is a NoSQL cloud database service that provides consistent performance at any scale. Hundreds of thousands of customers rely on DynamoDB for its fundamental properties: consistent performance, availability, durability, and a fully managed serverless experience. In 2021, during the 66-hour Amazon Prime Day shopping event, Amazon systems - including Alexa, the Amazon.com sites, and Amazon fulfillment centers, made trillions of API calls to DynamoDB, peaking at 89.2 million requests per second, while experiencing high availability with single-digit millisecond performance.
Since the launch of DynamoDB in 2012, its design and implementation have evolved in response to our experiences operating it. The system has successfully dealt with issues related to fairness, traffic imbalance across partitions, monitoring, and automated system operations without impacting availability or performance. Reliability is essential, as even the slightest disruption can significantly impact customers. This paper presents our experience operating DynamoDB at a massive scale and how the architecture continues to evolve to meet the ever-increasing demands of customer workloads.
We approach instantaneous mapping, converting images to a top-down view of the world, as a translation problem. We show how a novel form of transformer network can be used to map from images and video directly to an overhead map or bird’s-eye-view (BEV) of the world, in a single end-to-end network. We assume a 1-1 correspondence between a vertical scanline in the image, and rays passing through the camera location in an overhead map.
This lets us formulate map generation from an image as a set of sequence-to-sequence translations. Posing the problem as translation allows the network to use the context of the image when interpreting the role of each pixel. This constrained formulation, based upon a strong physical grounding of the problem, leads to a restricted transformer network that is convolutional in the horizontal direction only. The structure allows us to make efficient use of data when training, and obtains state-of-the-art results for instantaneous mapping of three large-scale datasets, including a 15% and 30% relative gain against existing best performing methods on the nuScenes and Argoverse datasets, respectively.
A/B tests, also known as online controlled experiments, have been used at scale by data-driven enterprises to guide decisions and test innovative ideas. Meanwhile, non-stationarity, such as the time-of-day effect, can commonly arise in various business metrics. We show that inadequately addressing non-stationarity can cause A/B tests to be statistically inefficient or invalid, leading to wrong conclusions. To address these issues, we develop a new framework that provides appropriate modeling and adequate statistical analysis for non-stationary A/B tests. Without changing the infrastructure for any existing A/B test procedure, we propose a new estimator that views time as a continuous covariate to perform post stratification with a sample-dependent number of stratification levels. We prove central limit theorem in a natural limiting regime under non-stationarity, so that valid large-sample statistical inference is available. We show that the proposed estimator achieves the optimal asymptotic variance among all estimators. When the experiment design phase of an A/B test allows, we propose a new time-grouped randomization approach to make a better balance on treatment and control assignments in presence of time non-stationarity. A brief account of numerical experiments are conducted to illustrate the theoretical analysis.
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
Bayesian optimization (BO) is a widely popular approach for the hyperparameter optimization (HPO) in machine learning. At its core, BO iteratively evaluates promising configurations until a user-defined budget, such as wall-clock time or number of iterations, is exhausted. While the final performance after tuning heavily depends on the provided budget, it is hard to pre-specify an optimal value in advance.
In this work, we propose an effective and intuitive termination criterion for BO that automatically stops the procedure if it is sufficiently close to the global optimum. Our key insight is that the discrepancy between the true objective (predictive performance on test data) and the computable target (validation performance) suggests stopping once the sub-optimality in optimizing the target is dominated by the statistical estimation error. Across an extensive range of real-world HPO problems and baselines, we show that our termination criterion achieves a better trade-off between the test performance and optimization time. Additionally, we find that overfitting may occur in the context of HPO, which is arguably an overlooked problem in the literature, and show how our termination criterion helps to mitigate this phenomenon on both small and large datasets.
Online advertising opportunities are sold through auctions, billions of times every day across the web. Advertisers who participate in those auctions need to decide on a bidding strategy: how much they are willing to bid for a given impression opportunity.
Deciding on such a strategy is not a straightforward task, because of the interactive and reactive nature of the repeated auction mechanism. Indeed, an advertiser does not observe counterfactual outcomes of bid amounts that were not submitted, and successful advertisers will adapt their own strategies based on bids placed by competitors. These characteristics complicate effective learning and evaluation of bidding strategies based on logged data alone.
The fundamental challenge of drawing causal inference is that counterfactual outcomes are not fully observed for any unit. Furthermore, in observational studies, treatment assignment is likely to be confounded. Many statistical methods have emerged for causal inference under unconfoundedness conditions given pre-treatment covariates, including: propensity score-based methods, prognostic score-based methods, and doubly robust methods. Unfortunately for applied researchers, there is no ‘one-size-fits-all’ causal method that can perform optimally universally. In practice, causal methods are primarily evaluated quantitatively on handcrafted simulated data. Such datagenerative procedures can be of limited value because they are typically stylized models of reality. They are simplified for tractability and lack the complexities of real-world data. For applied researchers, it is critical to understand how well a method performs for data at hand. Our work introduces a deep generative model-based framework, Credence, to validate causal inference methods. The framework’s novelty stems from its ability to generate synthetic data anchored at the empirical distribution for the observed sample, and therefore virtually indistinguishable from the latter. The approach allows the user to specify ground truth for the form and magnitude of causal effects and confounding bias as functions of covariates. Thus simulated data sets are used to evaluate the potential performance of various causal estimation methods when applied to data similar to the observed sample. We demonstrate Credence’s ability to accurately assess the relative performance of causal estimation techniques in an extensive simulation study and two real-world data applications from Lalonde and Project STAR studies.
Complementary product recommendation aims at providing product suggestions that are often bought together to serve a joint demand. Existing work mainly focuses on modeling product relationships at a population level, but does not consider personalized preferences of different customers. In this paper, we propose a framework for personalized complementary product recommendation capable of recommending products that fit the demand and preferences of the customers. Specifically, we model product relations and user preferences with a graph attention network and a sequential behavior transformer, respectively. The two networks are cast together through personalized re-ranking and contrastive learning, in which the user and product embedding are learned jointly in an end-to-end fashion. The system recognizes different customer interests by learning from their purchase history and the correlations among customers and products. Experimental results demonstrate that our model benefits from learning personalized information and outperforms non-personalized methods on real production data.