
Once upon a time, we could confidently pull on the threads of information around us and weave them into useful knowledge, because the higher-quality threads tended to stand out. Today, as we're swept along by an information tsunami, it can be hard to know what to reach for, what information to trust. Amazon Scholar Heng Ji, a professor of computer science at the University of Illinois Urbana-Champaign (UIUC), has made it her life’s work to help us separate the signal from the noise.

“It’s a challenge, but if we don't work on it, this is going to become a serious societal problem,” says Ji, who also directs the Amazon-Illinois Center on Artificial Intelligence for Interactive Conversational Experiences (AICE). “Helping people stay reliably informed, so they can make good choices: that’s my motivation.”

To that end, Ji leads the Blender Lab at UIUC, where she seeks to foster a future of information accessibility in which computers will be capable of discerning precise, succinct, and reliable knowledge from the information swirling through that tsunami. Not only that, she says, we will also be able to access this reliable knowledge by conversing with computers using natural language.
“We want to know who did what, to whom, where and when, entities, events and actions, claims and counter-claims, their interconnections, and then make sense of it all,” says Ji.
The key approach Ji brings to bear on this challenge is natural-language processing (NLP) and her pioneering work in information extraction (IE).
Situation reports
The roots of IE can be traced back to the Message Understanding Conference (MUC), a series of events that the Defense Advanced Research Projects Agency started in the late 1980s. The program was co-led by Ralph Grishman who would later become Ji’s PhD advisor. Today, Ji is bringing IE back to its roots with a technology her team revealed in March, called SmartBook, with support from the Defense Advanced Research Projects Agency (DARPA) and the U.S. National Science Foundation.
In times of disaster, such as a global pandemic, or ongoing conflicts such as the Russian invasion of Ukraine, good decision-making requires gathering comprehensive intelligence of the reality on the ground. In conflicts, this intel is referred to as situation reports (sitreps).
Analysts and humanitarian workers must gather and digest large amounts of up-to-date documents daily, then combine that with extensive local and cultural knowledge, and the broader dynamics of a disaster. Only then can analysts create useful sitreps that military leaders or politicians can use to make strategic decisions. It’s a tough process to automate.
In 2022, Ji came across the nonprofit organization Data Friendly Space, which produces a situational analysis of the Ukraine crisis every two weeks.
“I wanted to help this group by automating a first draft of their sitreps, so that they could spend time on what they are really good at — using their expertise to shape that draft, adding strategically important information and making recommendations.”
What Ji and her collaborators, led by Clare Voss at the US Army Research Laboratory, came up with was the SmartBook framework. Using the Ukraine crisis as a case study, the SmartBook digests large amounts of news data from the internet, automatically extracting information including events, places, people, weapons, and military actions and pulls it all together to produce sitreps.
The reports are structured within timelines featuring major events as chapters, with relevant strategic questions used as section headings and corresponding summaries across claims grounded with links to the sources of information (Fig 1). Everything is automatic.
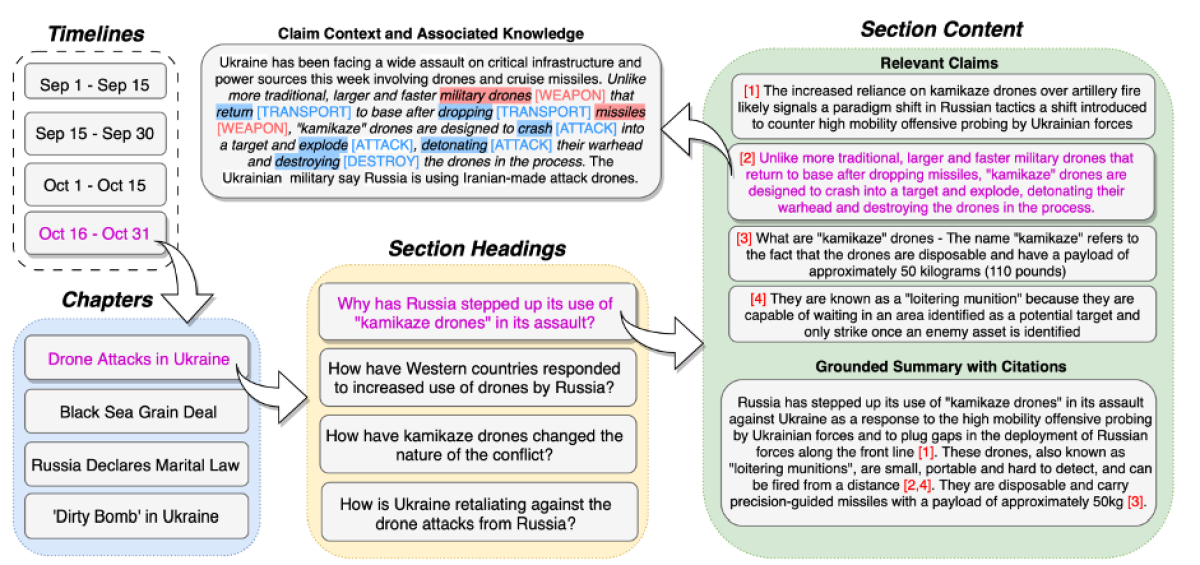
While the SmartBook uses large language models (LLMs) to produce the summaries (Fig 1, above, bottom right) conditioned on extracted claims from news sources, it is only one of many components in the SmartBook framework. ChatGPT alone, for example, could not generate a structured sitrep, not least because it is not trained on up-to-date information. And LLMs are prone to hallucinate, generating information or “answers” that are not grounded in the source news data, leading to outputs that can be inaccurate, misleading, or entirely fabricated.
When an expert analyst was asked to edit the sitreps produced by the SmartBook, they added more detail to the document but removed only about 2% of the content. “This indicates the SmartBook can act as a good starting point for analysts to expand upon for the generation of situation reports,” says Ji.
This early iteration of the SmartBook relies on news reports in English, but Ji’s team is currently increasing the variety of information sources and languages, to produce a more rounded picture.
Drug discovery
Another of Ji’s passions is applying her skills to support drug discovery. Ji envisions a future in which a doctor can write a few sentences describing a bespoke drug for treating a specific patient and then receive the exact structure of a drug with the desired characteristics, which could in turn be tested and synthesized to order. Currently, the development of a single novel drug can take over a decade and cost upwards of a billion dollars.

Ji and her team developed a novel learning framework that jointly represents molecules and language and enables translations between the two. “I was trained as a computational linguist, so I tend to see everything as a foreign language, and that includes molecules, images, or videos,” she says.
The framework is called MolT5 — a self-supervised-learning framework for pretraining models on a vast amount of unlabeled, natural-language text and molecule strings (a notation system that represents molecular structure). Given a molecule string, Ji and her team report that MotT5 will provide a text description that includes that molecule’s medicinal, atomic, and chemical properties. On the flip side, provide MolT5 with a description of desired molecular properties, and it will generate the string for a molecule that best fits that description.
The idea is that MolT5, or its descendants, will allow chemists to exploit AI technologies to discover new drugs using natural-language descriptions.
Human interactions
In March this year, Ji helped strengthen the relationship between Amazon and UIUC by becoming the founding director of AICE. AICE aims to develop new conversational AI systems that can automatically learn, reason, update their own knowledge, and interact in more modalities.
“If your digital assistant could also read the books and watch the movies that you have enjoyed, they will be able to conduct much more knowledgeable, informative, and interesting conversations with you," says Ji. "It would make interacting with them more natural — more human.”
Another focus of AICE is to improve the truthfulness, fairness, and transparency of conversational AI systems.
Can the modern information tsunami truly be tamed? “There's a trade-off between creativity and truthfulness,” Ji says, “but yes, I believe we can design novel algorithms to achieve both goals.”
Conversational-AI boom
Having spent her career working in NLP, what would Ji tell students who are considering it as an area of research, particularly in light of the LLM boom?
“First, keep your optimism! This LLM wave is exciting, although it has hit a lot of students hard, especially those already in the middle of their thesis,” Ji says. “While LLMs appear to close some research avenues, they open important new ones, such as structured prediction, cross-document reasoning, theoretical understanding of LLMs, factual-error correction, and so many more.”

Ji also notes the Chinese proverb “frequent moves make a tree die but a person prosperous” and recommends mixing academic and industry research. Ji herself has worked with the Alexa organization in her capacity as an Amazon Scholar since March. “I chose Amazon because it provided the opportunity to tackle real-world problems,” she says. For example, Ji is working with LLM teams at Amazon to, among other things, develop systems to minimize and prevent hallucinations.
“With Amazon, I want the ideas I've contributed to become part of the next generation of AI systems and for lots of customers to feel the benefit of that. It's a very different way of measuring success compared with academia, and that’s refreshing.”



