-
SIGIR 20192019Direct answering of questions that involve multiple entities and relations is a challenge for text-based QA. This problem is most pronounced when answers can be found only by joining evidence from multiple documents. Curated knowledge graphs (KGs) may yield good answers, but are limited by their inherent incompleteness and potential staleness. This paper presents QUEST, a method that can answer complex
-
EMNLP 2019 Workshop on Machine Reading for Question Answering2019We present a system for answering questions based on the full text of books (BookQA), which first selects book passages given a question at hand, and then uses a memory network to reason and predict an answer. To improve generalization, we pretrain our memory network using artificial questions generated from book sentences. We experiment with the recently published NarrativeQA corpus, on the subset of Who
-
IWSLT 20192019We evaluate three simple, normalization-centric changes to improve Transformer training. First, we show that pre-norm residual connections (PRENORM) and smaller initializations enable warmup-free, validation-based training with large learning rates. Second, we propose `2 normalization with a single scale parameter (SCALENORM) for faster training and better performance. Finally, we reaffirm the effectiveness
-
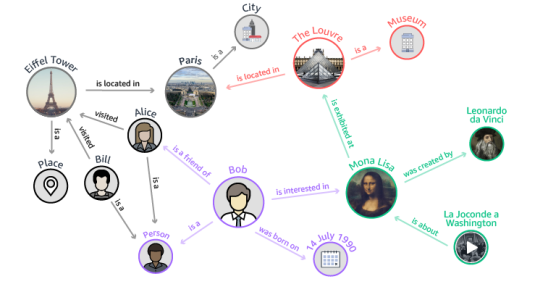
CIKM 20192019Fact-centric information needs are rarely one-shot; users typically ask follow-up questions to explore a topic. In such a conversational setting, the user’s inputs are often incomplete, with entities or predicates left out, and ungrammatical phrases. This poses a huge challenge to question answering (QA) systems that typically rely on cues in full-fledged interrogative sentences. As a solution, we develop
-
Interspeech 20192019This paper proposes a simple phone mapping approach to multi-dialect acoustic modeling. In contrast to the widely used shared hidden layer (SHL) training approach (hidden layers are shared across dialects whereas output layers are kept separate), phone mapping simplifies model training and maintenance by allowing all the network parameters to be shared; it also simplifies online adaptation via HMM-based
Related content
-
 March 05, 2019The 2018 Alexa Prize featured eight student teams from four countries, each of which adopted distinctive approaches to some of the central technical questions in conversational AI. We survey those approaches in a paper we released late last year, and the teams themselves go into even greater detail in the papers they submitted to the latest Alexa Prize Proceedings. Here, we touch on just a few of the teams’ innovations.
March 05, 2019The 2018 Alexa Prize featured eight student teams from four countries, each of which adopted distinctive approaches to some of the central technical questions in conversational AI. We survey those approaches in a paper we released late last year, and the teams themselves go into even greater detail in the papers they submitted to the latest Alexa Prize Proceedings. Here, we touch on just a few of the teams’ innovations. -
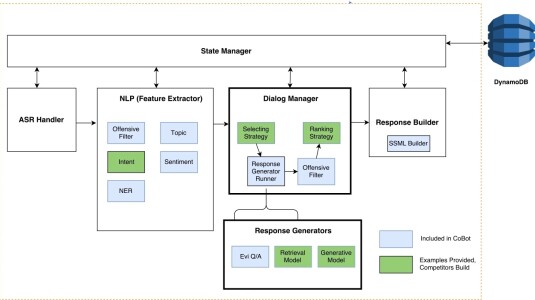
February 27, 2019To ensure that Alexa Prize contestants can concentrate on dialogue systems — the core technology of socialbots — Amazon scientists and engineers built a set of machine learning modules that handle fundamental conversational tasks and a development environment that lets contestants easily mix and match existing modules with those of their own design.
-
January 31, 2019This Sunday's Super Bowl between the New England Patriots and the Los Angeles Rams is expected to draw more than 100 million viewers, some of whom will have Alexa-enabled devices within range of their TV speakers. When Amazon's new Alexa ad airs, and Forest Whitaker asks his Alexa-enabled electric toothbrush to play his podcast, how will we prevent viewers’ devices from mistakenly waking up?
-
January 30, 2019Many of today’s most popular AI systems are, at their core, classifiers. They classify inputs into different categories: this image is a picture of a dog, not a cat; this audio signal is an instance of the word “Boston”, not the word “Seattle”; this sentence is a request to play a video, not a song. But what happens if you need to add a new class to your classifier — if, say, someone releases a new type of automated household appliance that your smart-home system needs to be able to control?
-
January 24, 2019Machine learning systems often act on “features” extracted from input data. In a natural-language-understanding system, for instance, the features might include words’ parts of speech, as assessed by an automatic syntactic parser, or whether a sentence is in the active or passive voice.
-
January 22, 2019Developing a new natural-language-understanding system usually requires training it on thousands of sample utterances, which can be costly and time-consuming to collect and annotate. That’s particularly burdensome for small developers, like many who have contributed to the library of more than 70,000 third-party skills now available for Alexa.