-
EMNLP 20192019Research in the social sciences and psychology has shown that the persuasiveness of an argument depends not only the language employed, but also on attributes of the source/communicator, the audience, and the appropriateness and strength of the argument’s claims given the pragmatic and discourse context of the argument. Among these characteristics of persuasive arguments, prior work in NLP does not explicitly
-
NeurIPS 2019 Workshop on Conversational AI2019Training dialog policies for speech-based virtual assistants requires a plethora of conversational data. The data collection phase is often expensive and time consuming due to human involvement. To address this issue, a common solution is to build user simulators for data generation. For the successful deployment of the trained policies into real world domains, it is vital that the user simulator mimics
-
EMNLP 20192019Enabling cross-lingual NLP tasks by leveraging multilingual word embedding has recently attracted much attention. An important motivation is to support lower resourced languages, however, most efforts focus on demonstrating the effectiveness of the techniques using embeddings derived from similar languages toEnglish with large parallel content. In this study, we present a noise tolerant piecewise linear
-
NeurIPS 2019 Workshop on Graph Representation Learning2019Short text classification is a fundamental problem in natural language processing, social network analysis, and e-commerce. Traditional approaches for classifying text do not generalize to short texts, due to the lack of structure that is prevalent in longer sentences and paragraphs. More recently, deep learning-based methods have been applied to this problem, with limited success. To overcome the limitations
-
IWSLT 2019 International Workshop on Spoken Language Translation2019The recent advances introduced by neural machine translation (NMT) are rapidly expanding the application fields of machine translation, as well as reshaping the quality level to be targeted. In particular, if translations have to fit some given layout, quality should not only be measured in terms of adequacy and fluency, but also length. Exemplary cases are the translation of document files, subtitles, and
Related content
-
 March 11, 2019In experiments involving sound recognition, technique reduces error rate by 15% to 30%.
March 11, 2019In experiments involving sound recognition, technique reduces error rate by 15% to 30%. -
March 05, 2019The 2018 Alexa Prize featured eight student teams from four countries, each of which adopted distinctive approaches to some of the central technical questions in conversational AI. We survey those approaches in a paper we released late last year, and the teams themselves go into even greater detail in the papers they submitted to the latest Alexa Prize Proceedings. Here, we touch on just a few of the teams’ innovations.
-
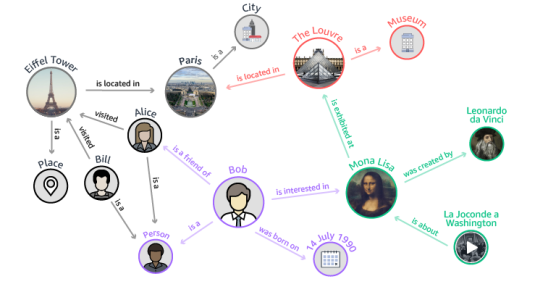
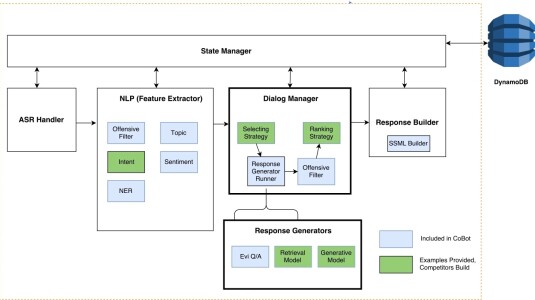
February 27, 2019To ensure that Alexa Prize contestants can concentrate on dialogue systems — the core technology of socialbots — Amazon scientists and engineers built a set of machine learning modules that handle fundamental conversational tasks and a development environment that lets contestants easily mix and match existing modules with those of their own design.
-
January 31, 2019This Sunday's Super Bowl between the New England Patriots and the Los Angeles Rams is expected to draw more than 100 million viewers, some of whom will have Alexa-enabled devices within range of their TV speakers. When Amazon's new Alexa ad airs, and Forest Whitaker asks his Alexa-enabled electric toothbrush to play his podcast, how will we prevent viewers’ devices from mistakenly waking up?
-
January 30, 2019Many of today’s most popular AI systems are, at their core, classifiers. They classify inputs into different categories: this image is a picture of a dog, not a cat; this audio signal is an instance of the word “Boston”, not the word “Seattle”; this sentence is a request to play a video, not a song. But what happens if you need to add a new class to your classifier — if, say, someone releases a new type of automated household appliance that your smart-home system needs to be able to control?
-
January 24, 2019Machine learning systems often act on “features” extracted from input data. In a natural-language-understanding system, for instance, the features might include words’ parts of speech, as assessed by an automatic syntactic parser, or whether a sentence is in the active or passive voice.