-
Interspeech 20192019Environmental sound classification systems often do not per-form robustly across different sound classification tasks and audio signals of varying temporal structures. We introduce a multi-stream convolutional neural network with temporal attention that addresses these problems. The network relies on three input streams consisting of raw audio and spectral features and utilizes a temporal attention function
-
EMNLP 20192019Natural Language Understanding (NLU) is a core component of dialog systems. It typically involves two tasks - intent classification(IC) and slot labeling (SL), which are then followed by a dialogue management (DM) component. Such NLU systems cater to utterances in isolation, thus pushing the problem of con-text management to DM. However, contextual information is critical to the correct prediction of intents
-
ICASSP 20192019This paper presents our work of training acoustic event detection (AED) models using unlabeled dataset. Recent acoustic event detectors are based on large-scale neural networks, which are typically trained with huge amounts of labeled data. Labels for acoustic events are expensive to obtain, and relevant acoustic event audios can be limited, especially for rare events. In this paper we leverage an Internet-scale
-
Interspeech 20192019Acoustic Event Detection (AED), aiming at detecting categories of events based on audio signals, has found application in many intelligent systems. Recently deep neural network significantly advances this field and reduces detection errors to a large scale. However how to efficiently execute deep models in AED has received much less attention. Meanwhile state-of-the-art AED models are based on large deep
-
Interspeech 20192019We present a hybrid approach for scaling distributed training of neural networks by combining Gradient Threshold Com-pression (GTC) algorithm - a variant of stochastic gradient de-scent (SGD) - which compresses gradients with thresholding and quantization techniques and Blockwise Model Update Filtering(BMUF) algorithm - a variant of model averaging (MA). In this proposed method we divide total number of
Related content
-
 October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions.
October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions. -
October 01, 2019Amazon today announced the public release of a new data set that will help speech scientists address the difficult problem of separating speech signals in reverberant rooms with multiple speakers. In the field of automatic speech recognition, this problem is known as the “cocktail party” or “dinner party” problem; accordingly, we call our data set the Dinner Party Corpus, or DiPCo.
-
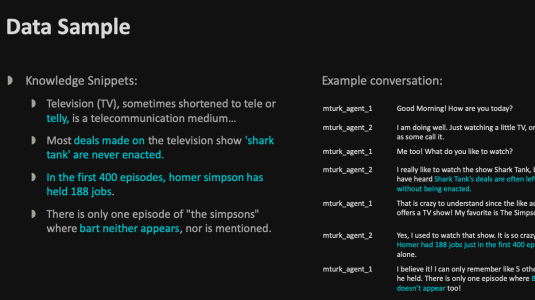
September 17, 2019Today I am happy to announce the public release of the Topical Chat Dataset, a text-based collection of more than 235,000 utterances (over 4,700,000 words) that will help support high-quality, repeatable research in the field of dialogue systems.
-
September 16, 2019During a conversation between a customer and a dialogue system like Alexa’s, the system must not only understand what the customer is saying currently but also remember the conversation history. Only by combining the history with the current utterance can the system truly understand the customer’s requirements.
-
Photo courtesy of Getty ImagesSeptember 10, 2019At next week’s Interspeech, the largest conference on the science and technology of spoken-language processing, Alexa researchers have 16 papers, which span the five core areas of Alexa functionality.
-
Animation by Nick LittleSeptember 05, 2019Earlier this year, we reported a speech recognition system trained on a million hours of data, a feat possible through semi-supervised learning, in which training data is annotated by machines rather than by people. These sorts of massive machine learning projects are becoming more common, and they require distributing the training process across multiple processors. Otherwise, training becomes too time consuming.