-
Interspeech 20202019We present a speech data corpus that simulates a “dinner party” scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at
-
AAAI 20192019Most modern neural machine translation (NMT) systems rely on presegmented inputs. Segmentation granularity importantly determines the input and output sequence lengths, hence the modeling depth, and source and target vocabularies, which in turn determine model size, computational costs of softmax normalization, and handling of out-of-vocabulary words...
-
WWW 2019 Workshop on ECNLP2019Product pages on e-commerce websites often overwhelm their customers with a wealth of data, making discovery of relevant information a challenge. Motivated by this, here, we present a novel framework to answer both factoid and non-factoid user questions on product pages. We propose several question-answer matching models leveraging both deep learned distributional semantics and semantics imposed by a structured
-
AKCB 20192019We present an approach for expanding taxonomies with synonyms, or aliases. We target large shopping taxonomies, with thousands of nodes. A comprehensive set of entity aliases is an important component of identifying entities in unstructured text such as product reviews or search queries. Our method consists of two stages: we generate synonym candidates from WordNet and shopping search queries, then use
-
NAACL 20192019Knowledge graph based simple question answering (KBSQA) is a major area of research within question answering. Although only dealing with simple questions, i.e., questions that can be answered through a single knowledge base (KB) fact, this task is neither simple nor close to being solved. Targeting on the two main steps, subgraph selection and fact selection, the research community has developed sophisticated
Related content
-
 October 17, 2019This year at EMNLP, we will cohost the Second Workshop on Fact Extraction and Verification — or FEVER — which will explore techniques for automatically assessing the veracity of factual assertions online.
October 17, 2019This year at EMNLP, we will cohost the Second Workshop on Fact Extraction and Verification — or FEVER — which will explore techniques for automatically assessing the veracity of factual assertions online. -
October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions.
-
October 01, 2019Amazon today announced the public release of a new data set that will help speech scientists address the difficult problem of separating speech signals in reverberant rooms with multiple speakers. In the field of automatic speech recognition, this problem is known as the “cocktail party” or “dinner party” problem; accordingly, we call our data set the Dinner Party Corpus, or DiPCo.
-
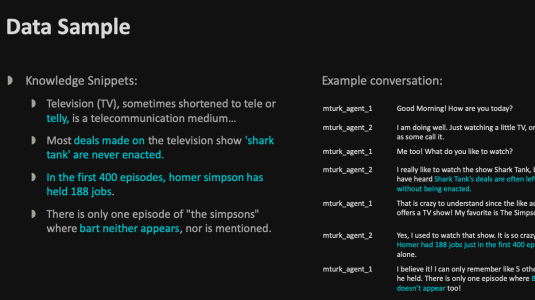
September 17, 2019Today I am happy to announce the public release of the Topical Chat Dataset, a text-based collection of more than 235,000 utterances (over 4,700,000 words) that will help support high-quality, repeatable research in the field of dialogue systems.
-
September 16, 2019During a conversation between a customer and a dialogue system like Alexa’s, the system must not only understand what the customer is saying currently but also remember the conversation history. Only by combining the history with the current utterance can the system truly understand the customer’s requirements.
-
Photo courtesy of Getty ImagesSeptember 10, 2019At next week’s Interspeech, the largest conference on the science and technology of spoken-language processing, Alexa researchers have 16 papers, which span the five core areas of Alexa functionality.