-
ICASSP 20192019We study media presence detection, that is, learning to recognize if a sound segment (typically lasting for a few seconds) of a long recorded stream contains media (TV) sound. This problem is difficult because non-media sound sources can be quite diverse (e.g. human voicing, non-vocal sounds and non-human sounds), and the recorded sound can be a mixture of media and non-media sound. Different from speech
-
ICASSP 20192019This paper presents our work of training acoustic event detection (AED) models using unlabeled dataset. Recent acoustic event detectors are based on large-scale neural networks, which are typically trained with huge amounts of labeled data. Labels for acoustic events are expensive to obtain, and relevant acoustic event audios can be limited, especially for rare events. In this paper we leverage an Internet-scale
-
ICASSP 20192019This is a report of our lessons learned building acoustic models from 1 Million hours of unlabeled speech, while labeled speech is restricted to 7,000 hours. We employ student/teacher training on unlabeled data, helping scale out target generation in comparison to confidence model based methods, which require a decoder and a confidence model. To optimize storage and to parallelize target generation, we
-
ICASSP 20192019Conventional far-field automatic speech recognition (ASR) systems typically employ microphone array techniques for speech enhancement in order to improve robustness against noise or reverberation. However, such speech enhancement techniques do not always yield ASR accuracy improvement because the optimization criterion for speech enhancement is not directly relevant to the ASR objective. In this work, we
-
ICASSP 20192019The use of spatial information with multiple microphones can improve far-field automatic speech recognition (ASR) accuracy. However, conventional microphone array techniques degrade speech enhancement performance when there is an array geometry mismatch between design and test conditions. Moreover, such speech enhancement techniques do not always yield ASR accuracy improvement due to the difference between
Related content
-
 October 28, 2019In a paper we’re presenting at this year’s Conference on Empirical Methods in Natural Language Processing, we describe experiments with a new data selection technique.
October 28, 2019In a paper we’re presenting at this year’s Conference on Empirical Methods in Natural Language Processing, we describe experiments with a new data selection technique. -
October 17, 2019This year at EMNLP, we will cohost the Second Workshop on Fact Extraction and Verification — or FEVER — which will explore techniques for automatically assessing the veracity of factual assertions online.
-
October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions.
-
October 01, 2019Amazon today announced the public release of a new data set that will help speech scientists address the difficult problem of separating speech signals in reverberant rooms with multiple speakers. In the field of automatic speech recognition, this problem is known as the “cocktail party” or “dinner party” problem; accordingly, we call our data set the Dinner Party Corpus, or DiPCo.
-
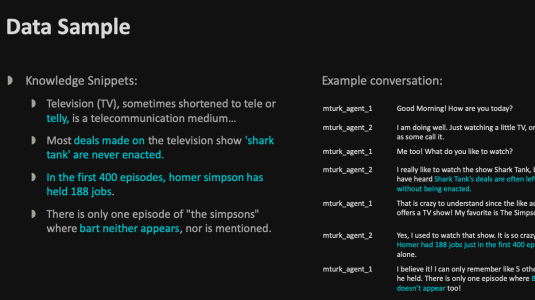
September 17, 2019Today I am happy to announce the public release of the Topical Chat Dataset, a text-based collection of more than 235,000 utterances (over 4,700,000 words) that will help support high-quality, repeatable research in the field of dialogue systems.
-
September 16, 2019During a conversation between a customer and a dialogue system like Alexa’s, the system must not only understand what the customer is saying currently but also remember the conversation history. Only by combining the history with the current utterance can the system truly understand the customer’s requirements.