-
International Conference on Neural Information Processing (ICONIP2023)2023In this work, we introduce a framework for cross-lingual speech synthesis, which involves an upstream Voice Conversion (VC) model and a downstream Text-To-Speech (TTS) model. The proposed framework consists of 4 stages. In the first two stages, we use a VC model to convert utterances in the target locale to the voice of the target speaker. In the third stage, the converted data is combined with the linguistic
-
INLG 20232023Prior art investigating task-oriented dialog and automatic generation of such dialogs have focused on single-user dialogs between a single user and an agent. However, there is limited study on adapting such AI agents to multiuser conversations (involving multiple users and an agent). Multi-user conversations are richer than single-user conversations containing social banter and collaborative decision making
-
SIGDIAL 20232023The bulk of work adapting transformer models to open-domain dialogue represents dialogue context as the concatenated set of turns in natural language. However, it is unclear if this is the best approach. In this work, we investigate this question by means of an empirical controlled experiment varying the dialogue context format from text-only formats (all recent utterances, summaries, selected utterances
-
ESEC/FSE 20232023ML-powered code generation aims to assist developers to write code in a more productive manner by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have pushed the boundary of code generation and achieved impressive performance.] However, the huge number of model parameters poses a significant challenge to their adoption in a typical
-
Robotics and Automation Letters2023Complex manipulation tasks often require robots with complementary capabilities to collaborate. We introduce a benchmark for LanguagE-Conditioned Multi-robot MAnipulation (LEMMA) focused on task allocation and longhorizon object manipulation based on human language instructions in a tabletop setting. LEMMA features 8 types of procedurally generated tasks with varying degree of complexity, some of which
Related content
-
 October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions.
October 11, 2019In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions. -
October 01, 2019Amazon today announced the public release of a new data set that will help speech scientists address the difficult problem of separating speech signals in reverberant rooms with multiple speakers. In the field of automatic speech recognition, this problem is known as the “cocktail party” or “dinner party” problem; accordingly, we call our data set the Dinner Party Corpus, or DiPCo.
-
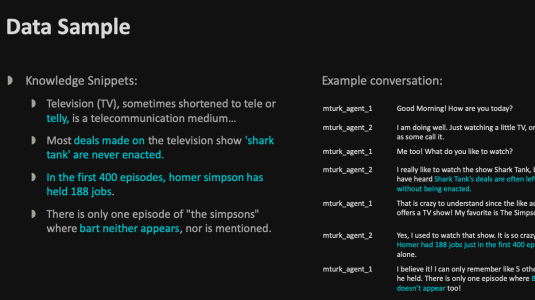
September 17, 2019Today I am happy to announce the public release of the Topical Chat Dataset, a text-based collection of more than 235,000 utterances (over 4,700,000 words) that will help support high-quality, repeatable research in the field of dialogue systems.
-
September 16, 2019During a conversation between a customer and a dialogue system like Alexa’s, the system must not only understand what the customer is saying currently but also remember the conversation history. Only by combining the history with the current utterance can the system truly understand the customer’s requirements.
-
Photo courtesy of Getty ImagesSeptember 10, 2019At next week’s Interspeech, the largest conference on the science and technology of spoken-language processing, Alexa researchers have 16 papers, which span the five core areas of Alexa functionality.
-
Animation by Nick LittleSeptember 05, 2019Earlier this year, we reported a speech recognition system trained on a million hours of data, a feat possible through semi-supervised learning, in which training data is annotated by machines rather than by people. These sorts of massive machine learning projects are becoming more common, and they require distributing the training process across multiple processors. Otherwise, training becomes too time consuming.