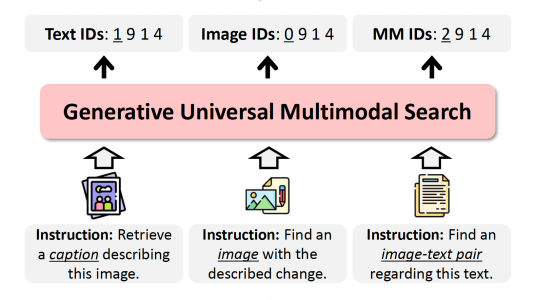
It was on a “hunting trip” to Italy in 2015 that computer vision pioneer Stefano Soatto first came across Alessandro Achille. More accurately, it was a mind-hunting trip, to the prestigious Scuola Normale Superiore in Pisa. The university was founded by Napoleon, and its alumni include Nobel-Prize-winning physicists Enrico Fermi and Carlo Rubbia and Field-Medal-winning mathematician Alessio Figalli. “It puts students through a grueling selection and training process,” says Soatto, “so those who survive are usually highly capable — and rugged.”
It was a successful trip that evolved into a powerful research partnership. Today, Achille is working as a senior applied scientist at Amazon Web Services' (AWS') AI Lab, on the California Institute of Technology (Caltech) campus, tackling fundamental challenges that are shaping the future of computer vision (CV) and large generative-AI models.
But back in 2015, Achille was immersed in a master’s in pure mathematics, “spiced up”, as he puts it, with algebraic topology.

“I don't remember a time in my life when I wasn't interested in science,” he says. Achille was particularly interested in the foundations of mathematics. “I focused on logic, because I’ve always had this nagging problem at the back of my mind of exactly why things are the way they are in mathematics.”
Achille’s first taste of computer vision arose when he and his peers decided to augment an annual school tradition: a 24-hour foosball tournament between mathematicians and physicists. Besides a sport competition, the event had become a showcase of the students’ engineering capabilities. That year, after adding live streaming and a fully automated scorekeeping system, the students thought it was time to add real-time tracking of the ball.
“It’s just a white blob moving on a green background. How hard could it be?” says Achille. The short answer is, harder than they thought. So Achille took a class that would teach him more — a choice that would eventually lead to an invitation from Soatto to join him at the University of California, Los Angeles, for a PhD in computer vision.
“In Italian education, it sometimes feels like there is a hierarchy,” says Achille. “The more abstract you are, the better you are doing!” So why the departure from pure mathematics? In the end, says Soatto, “Alessandro’s work became so abstract he couldn’t see a path to impact. That’s very frustrating for a really smart person who wants to make a difference in the world.”
Deep learning takes off
Achille’s PhD coincided with the rise of deep learning (DL), which would become a game-changing technology in machine learning and computer vision. “At the time, we didn't know if it was anything more than just a new, slightly more powerful tool. We didn’t know if DL had the power of abstraction, reasoning, and so on,” says Achille.

The power of deep learning was becoming clear, though. During an internship in 2017, Achille worked on a computer vision model that could learn a representation of a dynamic scene — a 3-D shape that was moving, changing color, changing orientation, and so on.
The idea was to capture and isolate the semantic components of the scene — shape, size, color, or angle of rotation — rather than capturing the totality of the scene’s characteristics. Humans do this disentangling naturally. That’s how you would understand the sight of a blue banana, even if you had never seen one before: “banana” and “blue” are separate semantic components.
While Achille enjoyed the project and appreciated its importance, he was struck by the artificiality of the setting. “I was not working backwards from a use case,” he says. Shortly after, Achille became an intern at the AWS AI Lab that had just been established at the Caltech campus, where he was immediately given a real-world challenge to solve on a newly launched product called Custom Label.
Real-world problems
At the time, Custom Label allowed Amazon customers to access CV models that could be trained to identify, say, their company’s products in images — a particular faucet, for example. The models could also be trained to perform tasks like identifying something in a video or analyzing a satellite image.
AWS researchers realized it was impractical to expect a single model to accurately deal with such a range of esoteric image possibilities. A better approach was to pretrain many expert models on different imagery domains and then select the most appropriate one to fine-tune on the customer’s data. The problem for AWS was, how could it efficiently discover which of 100 or more pretrained CV models would perform best?
During his research in machine learning, Achille became passionate about information theory — a mathematical framework for quantifying, storing, and communicating information. So he used that approach on this so-called model selection problem. “For a hammer, everything looks like a nail,” he laughs.
The problem is how to measure the “distance" between two learning tasks — the task a given AWS model has been pretrained on and the novel customer task. In other words, how much additional information is required by the pretrained model to produce a good performance on the customer task? The less additional information required, the better.
Achille was impressed by the task because it was an important customer issue with a fundamental mathematical problem behind it. “We formulated an algorithm to compute this efficiently, so we could easily select the expert model best suited to solving the customer’s task,” says Achille. “It was the first solution to this problem.”
Achille found Amazon’s applied approach to be a compelling way to work, and when Soatto established the AWS AI Labs, Achille was happy to join him there.
“One of the beauties of being at Amazon is that we’re tackling some of the world's most challenging emerging problems,” says Soatto. “Because when AWS customers have difficult problems to address, they come to us. From a scientific perspective, this is a goldmine.”
Machine unlearning
Achille is currently staking out a vein of research gold in a critical new area of artificial intelligence (AI): AI model disgorgement, more popularly known as "machine unlearning". It is critical in any implementation of machine learning models that the data used to train the model are used responsibly, in a privacy-preserving manner, and in accordance with the appropriate regulations and intellectual-property rights.

Modern ML models have become very large and complex, requiring a great deal of data and computational resources to train. But what if, once a model is trained, the contributor of some of those training data decides, or is obligated by law, to withdraw the data from the model? Or what if some of the training data is discovered to be biased? Retraining a large model afresh, with some data withheld, may be impractical, particularly if the requirement for such changes becomes commonplace in the shifting legal landscape.
The next level
In 2019 that Soatto, Achille, and Achille's fellow UCLA PhD student Aditya Golatkar published a paper entitled “Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks”; the paper established a novel method for removing the effects of a subset of a deep neural network's training data, without requiring retraining.
“I was happy to see interest in ‘selective forgetting’ explode after we published this paper,” says Achille. “Model disgorgement is a fascinating problem, and not only because it's very important for AWS customers. It also demands that we understand everything about a model’s neural network. We need to understand where information is held in a model’s weights, how it is encoded, how it is measured.”
It is in this fundamental work that Achille took the field to “the next level”, says Soatto. And this year, Achille and Soatto, on a team also featuring Amazon Scholar Michael Kearns, coauthor of the book The Ethical Algorithm, led the field by introducing a taxonomy of possible disgorgement methods applicable to modern ML systems.
The paper also describes ways to train future models so that they are amenable to subsequent disgorgement.

“It is better for models to learn in a compartmentalized fashion, so in the event that some data is found to be problematic, everything that touched those data gets thrown away, while the rest of the model survives without having to retrain it from scratch,” says Soatto.
This work has been particularly satisfying, says Achille, as it obliged computer scientists, mathematicians, lawyers, and policymakers to work closely together to solve a pressing modern problem.
Critical learning periods
The breadth of Achille’s interests is formidable. His other prominent research includes work on “critical learning periods” in the training of deep networks. The work arose through serendipity, after a friend studying for a medical exam on the profound effect of critical learning periods in humans jokingly asked Achille if his networks also had them. Interest piqued, Achille explored the idea, and found some striking similarities.
For example, take infantile strabismus, a condition in which a person's eyes do not align properly from birth or early infancy. If not treated early, the condition can cause amblyopia, whereby the brain learns to trust the properly working eye and to ignore the visual input from the misaligned eye, to avoid double vision.
This one-sided competition between the two eyes (data sources) leads to worsening vision in the misaligned eye and of course the loss of stereo vision, which is important for depth perception. Amblyopia is difficult to reverse if left untreated into adulthood. But treating the eyes early, enabling them to work together optimally, makes for a robust vision system.
Similarly, in the early training of multimodal deep neural networks, one type of data may become favored over another, simply through expediency. For example, in a visual-question-answering model, which is trained on images and captions, the easy-to-use textual information may outcompete visual information, leading to models that are effectively blind to visual information. Achille and his colleagues suggest that when a DL model takes such shortcuts, it has irreversible effects on the subsequent performance of the model, making it less flexible — and therefore less useful — when fine-tuned on novel data.
Off the charts
Having explored the causes of critical learning periods in deep networks, the team offered new techniques for stabilizing the early learning dynamics in model training and showed how this approach can actually prevent critical periods in deep networks. The practical benefits of this research aside, Achille enjoys exploring the parallelisms of artificial and biological systems.
“Look, we can all recognize that the actual hardware of a network and a brain are completely different, but can we also recognize that they are both systems that are trying to process information efficiently and trying to learn something?” he asks. Are there some fundamental dynamics of learning, and how it relates to the acquisition of information, that are shared between synthetic and biological systems? Watch this space.
Looking back on the eight years since his hunting trip to Pisa, Soatto considers what he most appreciates about his Amazon colleague.
“First, the brilliance of the way Alessandro frames problems: he thinks very abstractly, yet he is also a hacker who thinks broadly, all the way from mathematics to neuroscience, from art to engineering — this is very rare. Second, his curiosity, which is absolutely off the charts.”
For Achille’s part, when asked if he prefers tackling the challenges that arise from AWS products or working on fundamental science problems, he demurs. “I don’t need to split my time between product and fundamental research. For me, it ends up being the same thing.”
Indeed, one of Amazon’s most abstract thinkers has found a path to true impact.