

Twenty years ago — well before the deep-learning revolution — Yossi Keshet, an Amazon Scholar and associate professor of electrical and computer engineering at Israel’s Technion, was already working on the problem of automatic speech recognition.
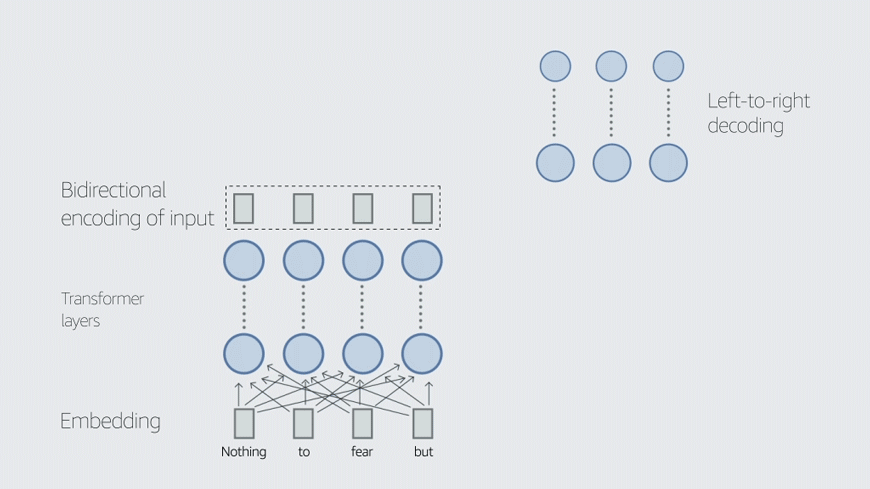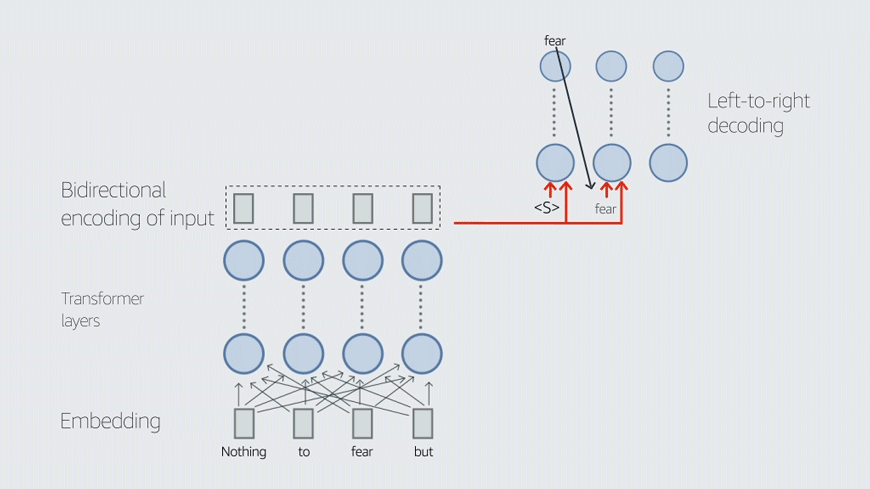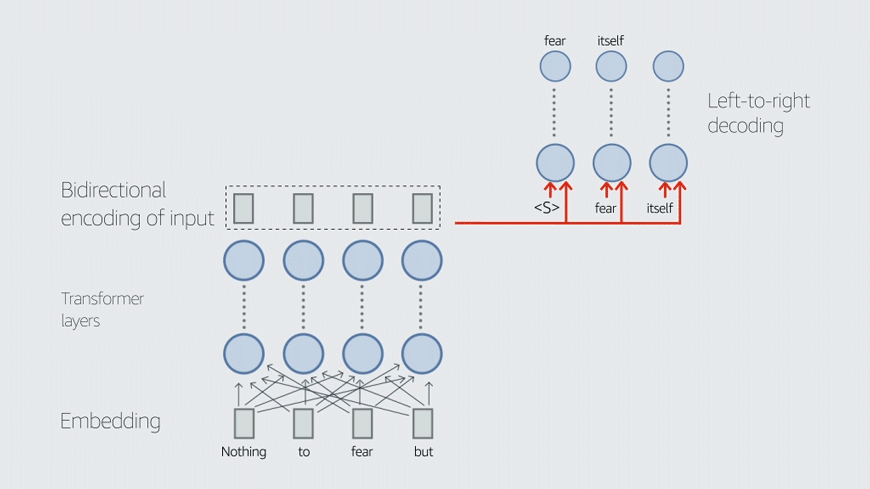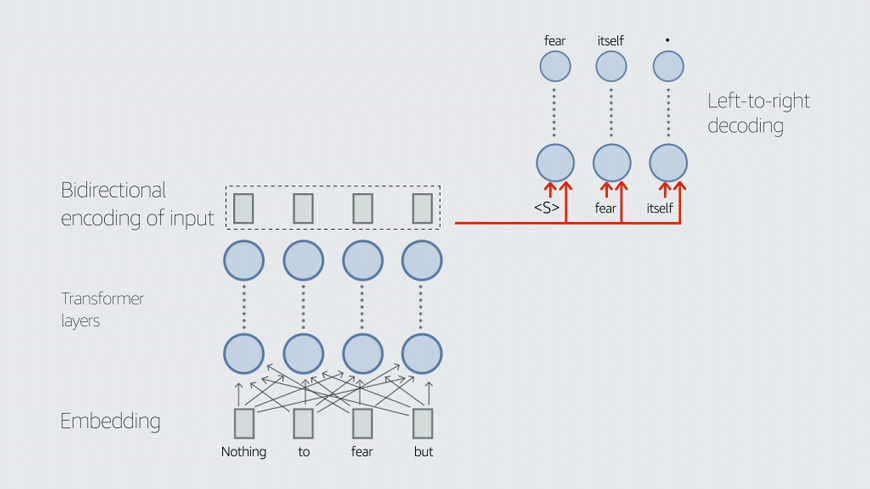
“The focus in the industry was on small-scale automatic speech recognition and on closed-vocabulary speech recognition, such as systems for connected-digit recognition, like ‘Call 26784’,” Keshet says. “We hear the digits of ‘26784’ as pronounced in isolation, but they are actually pronounced connected.”
Now, many of the best-performing AI models use deep learning, and millions of people rely on voice agents or transcription software on their phones to convert their speech into text. But that doesn’t mean speech recognition is a solved problem, Keshet says.
We still have gaps, especially in reverberant rooms, in pathological speech, in accented speech, in all the world languages.
“We still have gaps, especially in reverberant rooms, in pathological speech, in accented speech, in all the world languages,” Keshet says. “Sometimes, as humans, we can only understand speech based on context, because we have some kind of error-correcting mechanism at a higher level. Speech recognition systems still don't have that. And that's fascinating, because it's related to other things like communication theory and information theory.”
In particular, Keshet identifies two trends in speech-related research that have recently gained momentum.
“The first one is unsupervised/self-supervised mechanisms,” he says. “It means that the system itself gives more data to itself, to train itself, to adapt itself, you name it.
“The other subject is related to representation, but it's a new representation. We used to have a representation, the mel-spectrum, that is backed up with signal processing and our understanding of human hearing mechanisms. But it turns out that it’s possible to build representations that do not assume a particular structure of the signal, and they are better both for automatic speech recognition and for speech synthesis. The most effective representations are based on self-supervised learning, where unlabeled inputs define an auxiliary task that can generate pseudo-labeled training data. These data can be used to train models using supervised techniques.”
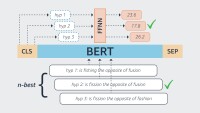
This new approach to representing acoustic data, Keshet explains, is inspired by the success of BERT models in natural-language processing (NLP). Today, it’s common to build NLP models by using relatively small corpora of annotated data to fine-tune pretrained language models, such as BERT, which encode word sequence probabilities for entire languages.
BERT is trained in an unsupervised fashion, meaning there’s no need for annotation of training data. Instead, words of sentences in the training data are randomly masked out, and the models learn to predict the missing words.
“Similarly, in speech, many self-supervised learning algorithms are based on training deep-learning models to distinguish subsequent from random future samples,” Keshet explains. “The rationale behind this concept is that subsequent samples are more likely to belong to the same phonemic class than random future samples.
“I can give you an example in the work that my academic research group did on speaker diarization, which is identifying who speaks when. You’re given a stream of speech, and you need to say, ‘This is A. This is B. This is A. This is C.’
“So in this work, we assume that in the next 10 milliseconds, it's supposed to be the same speaker, and also in the next 100 milliseconds. In the next second, who knows? But at least in the next 500 milliseconds, it's supposed to be the same speaker. You can also do it with phoneme segmentation” — matching segments of the raw acoustic signal to phonemes, the smallest units of speech.
“Another concept for self-supervised learning is called Barlow twins,” Keshet says. “You have two signals associated with the same speaker, phoneme, text, whatever you want. And you train a network that learns that they're supposed to be close in the representation space, whereas everything else is supposed to be not so close.
Can we build a system that gives almost perfect auditory and visual feedback to learners of a new language? Read my medium post on a new algorithm to generate synthetic feedback of proper pronunciation from the wrong one in the speaker’s own voice. https://t.co/d7gWnP526S
— Yossi Keshet (@jkeshet) August 7, 2022
“This is dramatic, because if you want to do speech recognition in an esoteric language like Hebrew, you can do it. You just need speech. It's something that we have never had before. It allows us to expand to languages that don't have huge data corpora.”

Sometimes, however, there just isn’t enough data of any kind, annotated or unannotated. And dealing with those situations is another open frontier in speech-related technology, Keshet says.
“Let me give you an example,” he says. “Listening to podcasts, sometimes you want to make the speech faster or slower. This works really badly. So my group decided to tackle this problem.
“The problem is we don't have data of you speaking at 1.2x, 1.33x, 0.8x. And even if we have recorded speech in which you speak faster or slower, we don't know which is which.
“We did the very first work on a deep-learning architecture to tackle this problem. And the data is not used in a supervised way. We make it faster and then go back and compare the two signals, and then we make it slower and compare those. We do different types of comparisons.
“Those are similar to the contrastive loss. The contrastive loss function has three elements. We compare the current frame to two other elements. One is positive, and one is negative. And the loss function will say, okay, take all the parameters of the network and make the positive one close and the negative one far away.
“This is a way of using unsupervised data in a way that makes things different. And it’s phenomenal quality. It's studio quality.”
Twenty years after he began working on speech-related technologies, then, Keshet’s enthusiasm remains undiminished.
“I can't help it,” he says. “I'm excited about human speech, which is one of the most trivial yet one of the most complex signals we know.”



